数据来源:Arena WebDev Leaderboard 与 Agent Arena Leaderboard,抓取日期 2026-06-16。 本文所有结论均基于上述公开榜单的实测数据,并对置信区间(误差棒)做了说明——这点对正确解读排名至关重要。
一、先说结论
GLM-5.2(Max)是当前"性价比断层级"的开源旗舰模型。
- 在 WebDev(前端网页开发) 榜上排名 第 2,紧追 Anthropic 的旗舰 Claude Fable 5,且把 Claude Opus 4.6/4.7/4.8、GPT-5.5 等一众更贵、更"封闭"的模型压在身后。
- 在 Agent(智能体/工具编排) 榜上排名 第 10,单看名次不算顶尖,但它的"任务确认成功率"是全场第二高,宽置信区间意味着真实排名可能在第 6~13 名之间浮动。
- 同时它是 MIT 协议开源、价格仅 1.40/4.40(输入/输出,每百万 token),是同档位模型里最便宜的之一。
一句话:用闭源旗舰几分之一的钱,拿到接近、甚至在某些维度超过闭源旗舰的能力。
二、WebDev 榜:GLM-5.2 是"挑战者"位置
WebDev 榜衡量模型在前端开发任务上的整体水平,包含多步推理与工具调用的 agentic 编码能力。排名越高,意味着在真实网页开发场景里越能交付可用代码。
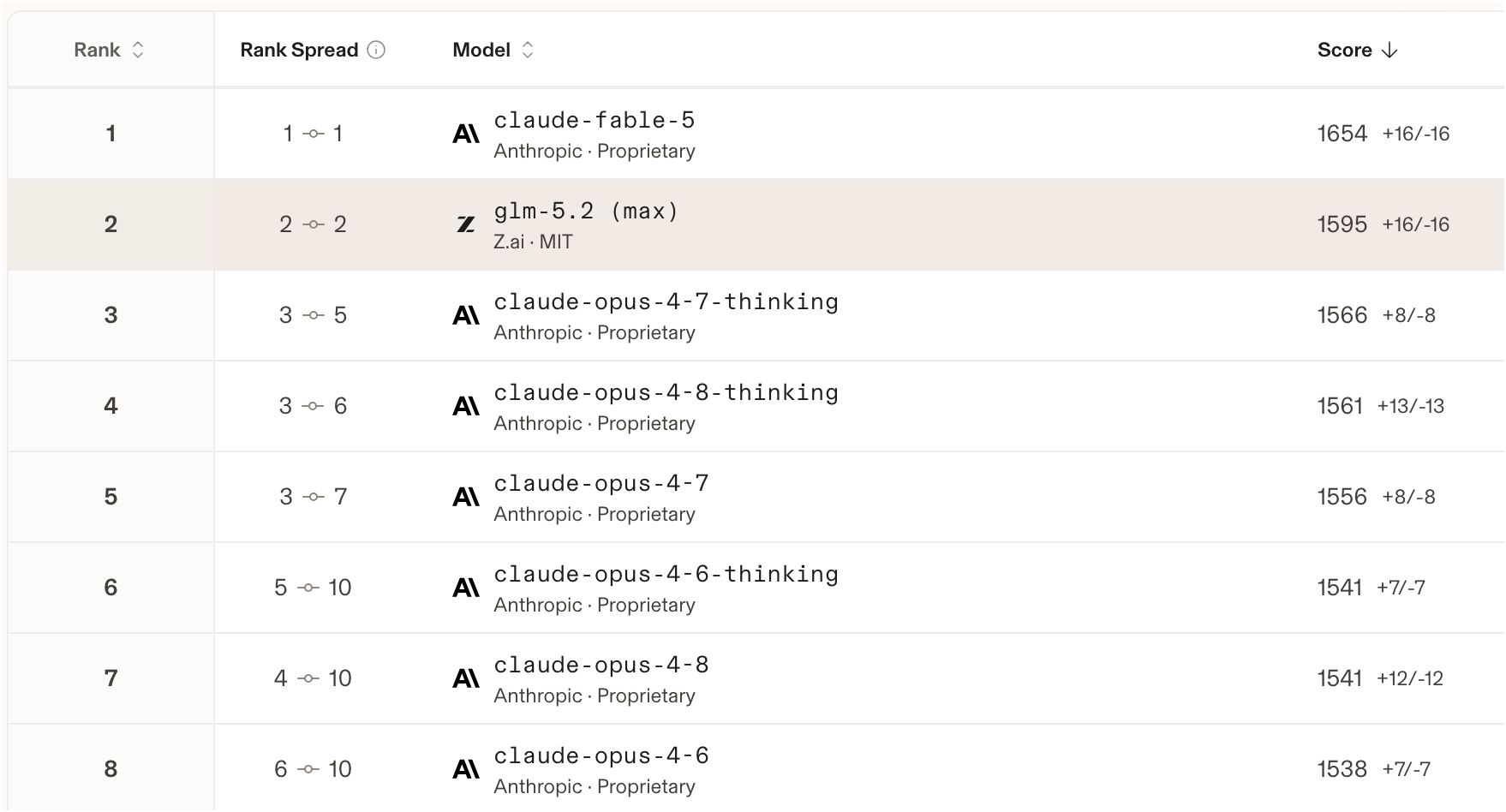
榜单头部(节选)
| 排名 | 模型 | 分数 | 价格 输入/输出,$/M | 上下文 |
|---|---|---|---|---|
| 🥇 1 | claude-fable-5(Anthropic) | 1654 | 10/50 | 1M |
| 🥈 2 | glm-5.2 max(Z.ai, MIT) | 1595 | 1.40/4.40 | 1M |
| 🥉 3 | claude-opus-4-7-thinking(Anthropic) | 1566 | 5/25 | 1M |
| 4 | claude-opus-4-8-thinking(Anthropic) | 1561 | 5/25 | 1M |
| 5 | claude-opus-4-7(Anthropic) | 1556 | 5/25 | 1M |
| 6 | claude-opus-4-6-thinking(Anthropic) | 1541 | 5/25 | 1M |
| 7 | claude-opus-4-8(Anthropic) | 1541 | 5/25 | 1M |
| 8 | claude-opus-4-6(Anthropic) | 1538 | 5/25 | 1M |
| 9 | glm-5.1(Z.ai, MIT) | 1531 | 1.40/4.40 | 202.8K |
怎么看这个第 2 名
1. 它是头部唯一一个开源模型。 前 8 名除了 GLM-5.2 自己,清一色是 Anthropic 的闭源 Claude Opus/Fable 系列。GLM-5.2 以开源身份挤进并稳住第 2,本身就是里程碑式的事件。
2. 它把"一整个 Claude Opus 家族"压在身后。 Opus 4.6/4.7/4.8(含 Thinking 版本)全部低于 GLM-5.2。换言之,在网页开发这个赛道,GLM-5.2 已经领先于 Anthropic 的 Opus 主力线,只输给更新、更强的 Fable 5。
3. 价格断层。 与第 1 名 Claude Fable 5 相比:
- 分数差距:1654 → 1595,落后约 3.6%。
- 价格差距:输入便宜约 7 倍,输出便宜约 11 倍。
- 也就是说,用户只需付出大约 1/10 的成本,就能拿到与最强闭源模型相差不到 4% 的网页开发能力。对于大量预算敏感的团队和个人开发者,这个权衡极具吸引力。
4. 投票数说明可信度。 GLM-5.2 拿到 1,641 次投票,排位置信区间为 ±16。虽不及 Claude Opus 家族动辄数千上万票那样"厚实",但已足以支撑它稳居第 2 这个结论。
三、Agent 榜:排名第 10,但"含金量"被低估了
Agent Arena 衡量的是模型在真实世界中编排工具完成 agentic 任务的能力,指标比单一分数更立体:净改进(Net Improvement)、确认成功率(Confirmed Success)、好评/差评比(Praise vs Complaint)、可控性(Steerability)、Bash 恢复能力(Bash Recovery)、工具幻觉率(Tool Hallucination)。
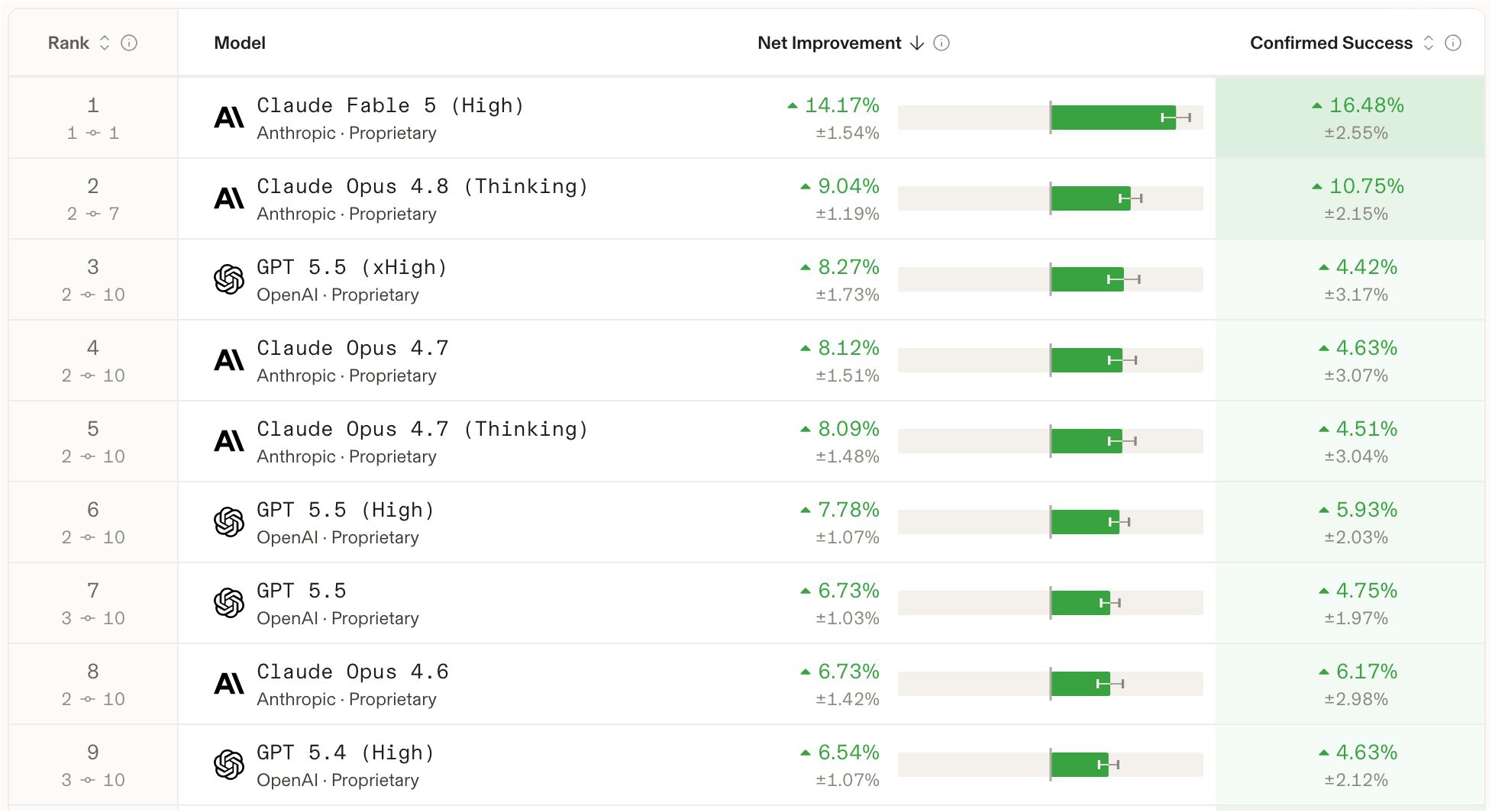
GLM-5.2 的各项指标
| 维度 | GLM-5.2 Max | 全场第 1(Claude Fable 5) | 说明 |
|---|---|---|---|
| 净改进 | 4.37% ±2.48% | 14.17% ±1.54% | 综合排名指标,GLM 列第 10 |
| 确认成功率 | 9.43% ±4.52% | 16.48% ±2.55% | ⭐ GLM 为全场第二高 |
| 好评/差评比 | 14.88% ±9.11% | 29.65% ±5.72% | 用户主观评价偏高 |
| 可控性 | 6.00% ±4.50% | 13.39% ±2.94% | 中等 |
| Bash 恢复 | 1.69% ±3.28% | 9.46% ±1.84% | ⚠️ 明显偏弱(区间跨零) |
| 工具幻觉率 | 1.86% ±0.23% | 1.86% ±0.23% | 与头部持平 |
几个被名次掩盖的关键事实
1. 确认成功率全场第二,比很多排名更高的模型还高。
把排名在 GLM-5.2 之前的几个模型的"确认成功率"拉出来对比:
| 模型(Agent 榜排名) | 确认成功率 |
|---|---|
| Claude Fable 5(#1) | 16.48% |
| GLM-5.2 Max(#10) | 9.43% |
| Claude Opus 4.6(#8) | 6.17% |
| GPT-5.5 High(#6) | 5.93% |
| Claude Opus 4.7(#4) | 4.63% |
| GPT-5.4 High(#9) | 4.63% |
| Claude Opus 4.7 Thinking(#5) | 4.51% |
| GPT-5.5(#7) | 4.75% |
| GPT-5.5 xHigh(#3) | 4.42% |
也就是说,当任务真正被"确认完成"时,GLM-5.2 的表现强于排名 #3~#9 的所有模型,仅次于 Claude Fable 5。这说明它的"硬交付能力"被综合排名低估了。当然 9.43% ±4.52% 的误差棒较宽,真实值区间为约 4.9%~13.9%,仍属中上水平。
2. 用户口碑(好评/差评比)相当好。 14.88% 这个数字与 Claude Opus 4.8 Thinking(14.36%)相当,高于 Claude Opus 4.7(10.73%)等模型。说明实际使用者对它的主观体验是偏正面的。不过 ±9.11% 的置信区间同样很宽,需更多样本收敛。
3. 工具幻觉率与头部持平。 1.86% ±0.23%,和 Claude Fable 5、GPT-5.5 等完全一致——在"不乱编工具调用"这件事上,GLM-5.2 没有短板。
4. ⚠️ 真正的短板是 Bash 恢复能力。 1.69% ±3.28%,置信区间下界为负值(约 -1.59%),意味着这个指标甚至可能没有正向贡献。对比头部模型(Claude Fable 5 为 9.46%,GPT-5.5 xHigh 为 14.42%),GLM-5.2 在"命令行出错后能否自我纠正、恢复执行"这一项上明显落后。这是它作为 agentic 模型目前最需要补强的地方——尤其在长链路、需要反复试错的终端任务里,这一弱点会被放大。
5. 为什么综合排名只有第 10? Agent 榜的"净改进"是一个聚合指标,综合了任务完成度、可靠性、可控性等多维信号。GLM-5.2 在"确认成功率"和"口碑"上强,但在"Bash 恢复"和"可控性"上偏弱,加上整体误差棒较宽,所以综合排到了第 10。但请注意:它仍然排在 Claude Opus 4.8、Claude Sonnet 4.6、GLM-5.1、DeepSeek V4 Pro、Gemini 3.5 Flash 之前。
四、代际进步:GLM-5.1 → GLM-5.2 跨越明显
把两代模型放在一起看,5.2 的进步是实打实的:
| 维度 | GLM-5.1 | GLM-5.2 Max | 提升 |
|---|---|---|---|
| WebDev 排名 / 分数 | 第 9 / 1531 | 第 2 / 1595 | ↑ 7 名,+64 分 |
| Agent 排名 / 净改进 | 第 13 / 2.66% | 第 10 / 4.37% | ↑ 3 名,+1.71 个百分点 |
| Agent 确认成功率 | 3.42% | 9.43% | 接近 3 倍 |
值得注意:5.1 在 WebDev 榜的上下文只有 202.8K,而 5.2 已扩展到 1M——长上下文能力的提升,很可能也是它在复杂网页开发任务上跃升的重要原因之一。
这是一次"质变级"的迭代:不仅排名大幅前移,在最能反映"真把活干完"的确认成功率上接近翻倍。
五、开源 + 价格:GLM-5.2 的真正护城河
技术和排名之外,有两点让 GLM-5.2 的战略价值远超分数本身:
1. MIT 协议开源。 在 WebDev 头部全是 Anthropic 闭源模型的环境下,GLM-5.2 是唯一一个可以自由使用、修改、部署、甚至商业化的开源选手。对于需要私有化部署、数据不出域、或做二次研发的团队(企业、研究机构、国内厂商),这是闭源模型无法提供的。
2. 价格碾压级优势。 同样是 1M 上下文,GLM-5.2 的 1.40/4.40 与 Claude Opus 家族的 5/25、Claude Fable 5 的 10/50 相比,便宜了数倍到十余倍。结合它在 WebDev 榜第 2 的实力,单位美元产出的代码质量,GLM-5.2 几乎是当前市场上最优解之一。
六、GLM-5.2 适合谁?短板在哪?
✅ 适合的场景
- 前端 / 全栈网页开发:WebDev 第 2 的实力,性价比无敌,尤其适合高频调用、批量生成 UI 代码的场景。
- 预算敏感的团队:用闭源旗舰零头的预算拿到接近的能力。
- 需要私有化 / 开源可控的场景:MIT 协议 + 可本地部署,满足合规与定制需求。
- 需要长上下文的任务:1M 上下文,适合大型代码库的阅读与修改。
- 需要"把活真正干完"的任务:确认成功率全场第二,交付可靠性优于多名次更高的对手。
⚠️ 需要注意的短板
- 重度依赖 Bash/命令行自我纠错的 agentic 任务:Bash 恢复能力偏弱且不确定,在需要反复试错、从终端错误中恢复的长链路任务上,可能不如 Claude Fable 5 或 GPT-5.5 稳健。建议在这类场景里配合更强的错误处理/重试机制,或等待后续版本补强。
- 可控性(Steerability)中等:需要精细操控模型行为时,体验不如头部闭源模型。
七、总评
| 维度 | 评价 |
|---|---|
| 前端开发能力 | ⭐⭐⭐⭐⭐(WebDev 第 2,开源第一) |
| Agentic 综合能力 | ⭐⭐⭐⭐(第 10,但确认成功率第 2,Bash 恢复偏弱) |
| 性价比 | ⭐⭐⭐⭐⭐(断层级领先) |
| 开放性 | ⭐⭐⭐⭐⭐(MIT 开源) |
| 代际进步 | ⭐⭐⭐⭐⭐(较 5.1 全面跃升) |
GLM-5.2 的意义不仅是一个"排名不错的模型",而是证明了开源阵营已经能够在最热门的网页开发赛道上,与最强闭源旗舰正面对抗,并以极其激进的定价把高端能力"平民化"。 它在 Agent 维度的 Bash 恢复短板,则是下一代(GLM-5.3?)最值得期待的改进方向。
对于绝大多数开发者和团队,GLM-5.2 是当前"闭源旗舰平替"里最值得认真考虑的选择——尤其当你的预算、合规需求或定制需求,让你无法直接用 Claude / GPT 时。