循环工程正在取代你亲自向智能体写提示词的角色。你不再亲自操作,而是设计一套系统来代替你完成这件事。这里的"循环"可以被理解为一个递归目标——你定义一个目的,AI 持续迭代直到完成。我相信这可能是我们与编程智能体协作的未来。不过,现在还早,我对此也持谨慎态度,而且你必须对 token 成本保持警惕(使用模式会因你的 token 资源多寡而大相径庭),所以我想深入探讨它到底是什么、意味着什么。
Peter Steinberger 最近说道:"你不应该再亲自向编程智能体写提示词了。你应该设计那些向智能体发出提示的循环。"类似地,Anthropic 的 Claude Code 负责人 Boris Cherny 也说过:"我已经不再亲自提示 Claude 了。我有循环在运行,它们向 Claude 发出提示并决定该做什么。我的工作就是编写循环。"
好吧,那这到底是什么意思?
大约两年来,你从编程智能体那里获得成果的方式一直是:写一个好的提示词,分享足够的上下文。你输入一段指令,阅读返回结果,再输入下一段。智能体是一个工具,而你从头到尾都握着它,一轮接一轮。这个阶段正在结束,或者至少有些人认为它将要结束了。
现在,你要构建一个小系统——它能自动发现工作、分配工作、检查工作、记录完成情况,然后决定下一步,并且由这个系统代替你去驱动智能体。我之前写过与此相关的概念——智能体驾具工程,即打造单个智能体运行的环境,以及工厂模型——构建软件的系统。循环工程则位于驾具之上的一层。驾具加上了定时器,能衍生出小助手,并且能自我喂养。
让我惊讶的是,这不再是一个工具层面的事情了。一年前,如果你想要一个循环,你得写一大堆 bash 脚本并永久维护它,那是你独有的东西。现在,这些组件已经内置在产品中了。Steinberger 的清单几乎与 Codex 应用完全对应,Claude Code 也几乎如此。而一旦你意识到这些产品的形态是相同的,你就不再争论用哪个工具了,而是设计一个无论在哪个工具中都能正常运行的循环。
循环的五大组件
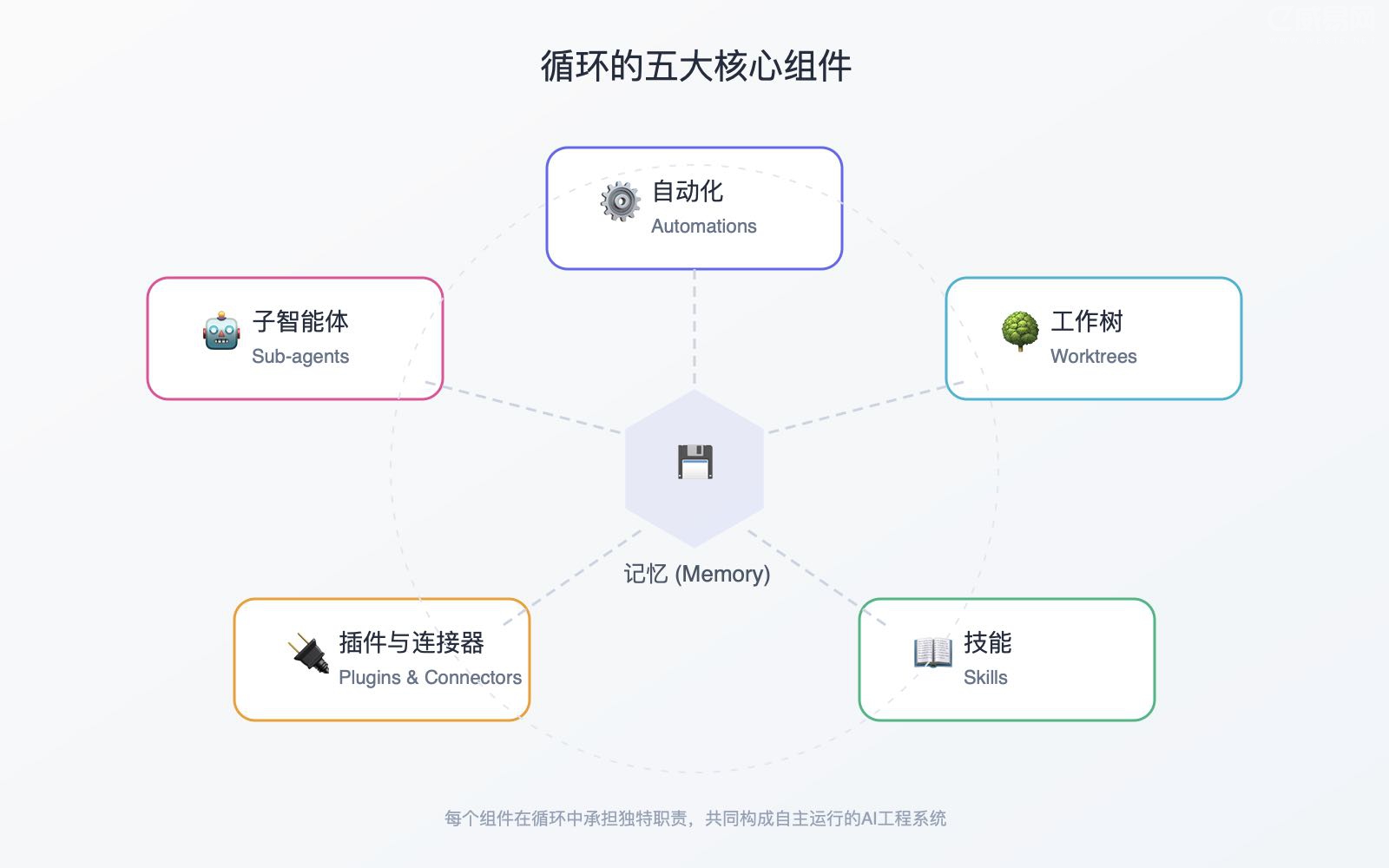
一个循环需要五样东西,外加一个记忆存储的地方。让我先列出清单,然后再逐一展开。
-
自动化(Automations):按计划触发,自动完成发现与分诊。
-
工作树(Worktrees):让两个并行工作的智能体互不干扰。
-
技能(Skills):将项目知识固化下来,否则智能体只能靠猜。
-
插件与连接器(Plugins & Connectors):将智能体接入你已有的工具。
-
子智能体(Sub-agents):让一个智能体提出方案,另一个来检查。
然后是第六样东西——记忆。一个 Markdown 文件,或者一个 Linear 看板,任何存在于单次对话之外、记录已完成工作和待办事项的东西。听起来简单到不重要。但这正是每个长时间运行的智能体所依赖的关键技巧,我在长时间运行的智能体一文中详细讨论过:模型在两次运行之间会忘记一切,所以记忆必须存储在磁盘上,而不是上下文中。智能体会遗忘,但代码仓库不会。
两个产品现在都已具备这五项能力。
|
循环中的基础能力 |
Codex 应用 |
Claude Code |
|---|---|---|
|
自动化(发现+分诊,按计划运行) |
自动化标签页:选择项目、提示词、频率、环境;结果进入分诊收件箱;/goal 表示运行直到完成 |
定时任务与 cron,/loop,/goal,hooks,GitHub Actions |
|
工作树(隔离并行功能) |
每个线程内置 worktree |
git worktree,--worktree,子智能体上的 isolation: worktree |
|
技能(固化项目知识) |
Agent Skills(SKILL.md),通过 $name 或隐式调用 |
Agent Skills(SKILL.md) |
|
插件/连接器(连接你的工具) |
连接器(MCP)+ 分发用插件 |
MCP 服务器 + 插件 |
|
子智能体(构思与验证) |
子智能体,以 TOML 定义于 .codex/agents/ |
任务子智能体,定义于 .claude/agents/,智能体团队 |
|
状态(跟踪完成情况) |
通过连接器的 Markdown 或 Linear |
Markdown(AGENTS.md、进度文件)或通过 MCP 的 Linear |
各处的名称略有不同,但能力是相同的。让我逐一展开,因为坦率地说,一个循环能否稳固运转还是悄悄崩溃,全在细节里。
自动化:让循环真正循环起来
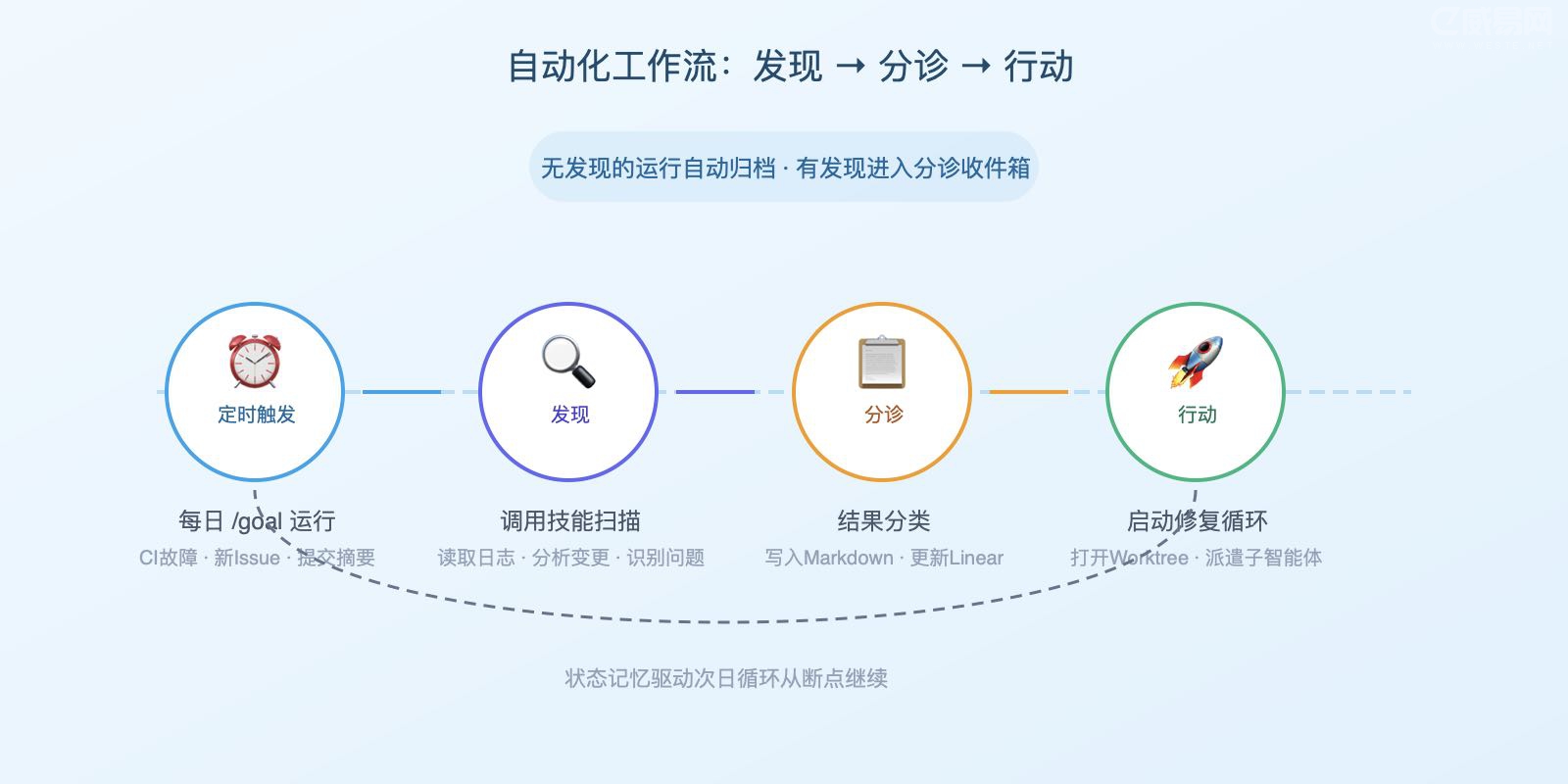
自动化是让循环成为真正循环的东西,而不只是你运行过的一次操作。在 Codex 应用中,你可以在"自动化"标签页创建一个,选择项目、它要运行的提示词、运行频率,以及它是在你本地的代码检出上运行还是在后台工作树上运行。发现有价值的运行会进入分诊收件箱,而没有发现的运行会自动归档——这很贴心。OpenAI 内部将这些自动化用于一些无聊的事情,比如每日 issue 分诊、CI 故障汇总、提交摘要、追踪上周某人引入的 bug。自动化还可以调用技能,这让循环任务变得可维护——你触发 $skill-name,而不是将一大段指令粘贴到一个没人会更新的计划里。
Claude Code 通过调度和 hooks 达到同样的效果。你可以用 /loop 按固定间隔运行一个提示或命令,可以安排 cron 定时任务,可以用 hooks 在智能体生命周期的特定节点触发 shell 命令,或者将整个流程推到 GitHub Actions,这样即使你合上笔记本它也能继续运行。完全相同的思路——你定义一个自主任务,给它一个执行节奏,结果自动呈送到你面前,这样你就不需要自己到处检查了。
还有一个值得了解的会话内原语,它更接近这篇文章的核心主题。/loop 按节奏重复运行。/goal 则持续运行直到你写下的某个条件真正成立,每一轮结束后,一个独立的小模型会检查是否已完成——这样写代码的智能体不是自己评分的那个。你可以给它类似"test/auth 中的所有测试通过且 lint 无报错"的目标,然后走开。Codex 也有同样的东西,也叫 /goal——它跨轮次持续工作,直到一个可验证的停止条件成立,支持暂停、恢复和清除。相同的原语,两个工具都有——这基本上是本文的一个贯穿模式。
所以这是负责发现工作的部分。循环的其余部分则负责处理工作。
工作树:并行而不冲突
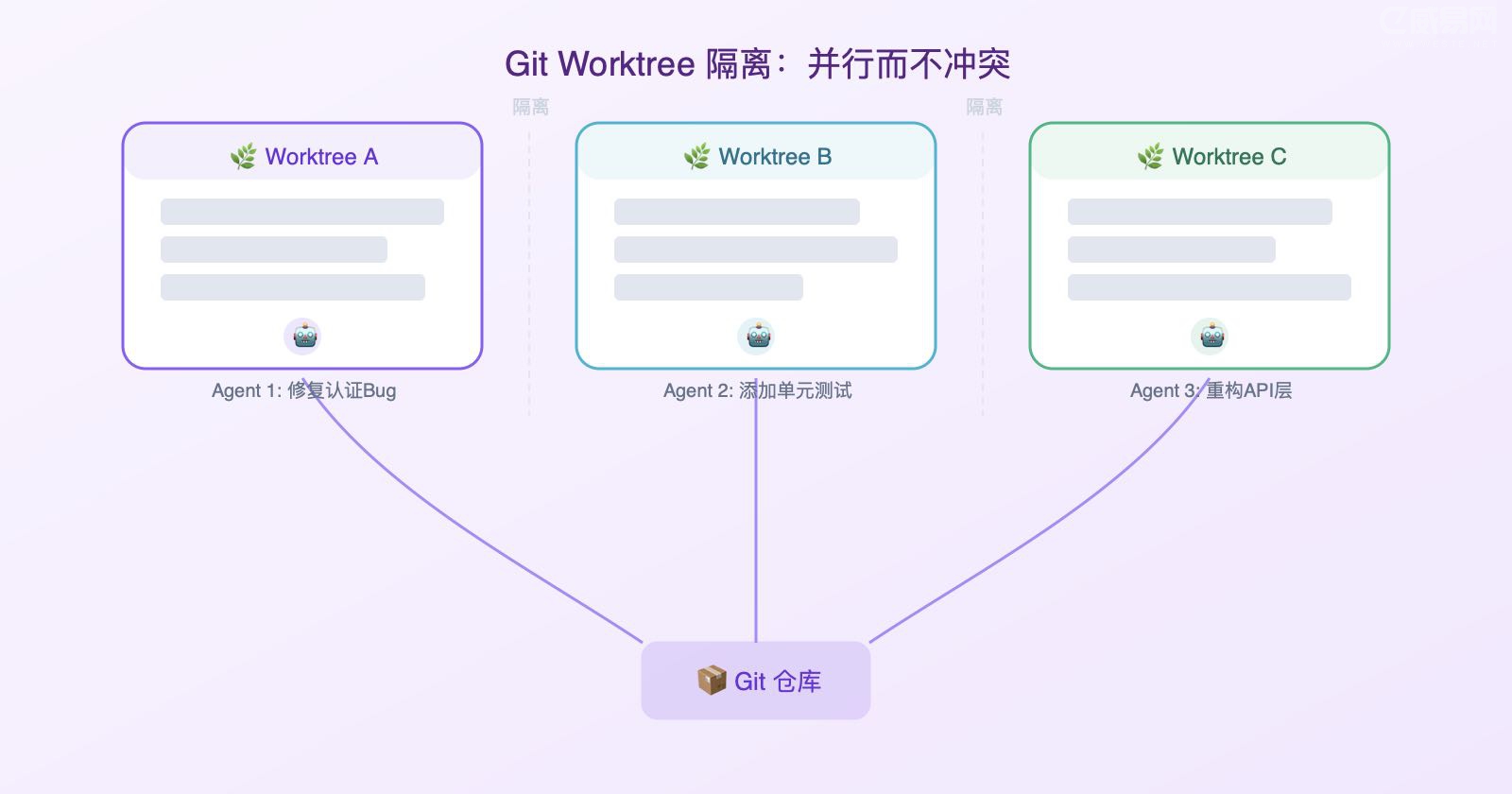
一旦你同时运行多个智能体,文件冲突就开始了——这就是故障所在。两个智能体同时写同一个文件,和两个工程师在没有沟通的情况下提交同一行代码,是完全一样的头痛。Git worktree 解决了这个问题:它是一个独立的工作目录,在自己的分支上,共享同一个仓库历史,因此一个智能体的编辑根本无法触碰另一个智能体的检出。
Codex 内置了 worktree 支持,因此多个线程可以同时命中同一个仓库而互不干扰。Claude Code 通过 git worktree、--worktree 标志(在新的独立检出中打开会话)以及 isolation: worktree 设置(贴在子智能体上,让每个助手获得一个全新的、完成后自动清理的检出)来实现同样的隔离。我在编排税一文中讨论了这一切的人为因素——worktree 消除了机械性的冲突,但你仍然是天花板,你的审查带宽决定了你实际能同时运行多少个,而不是工具。
技能:停止每次都从零解释
技能是你用来停止像金鱼一样每次会话都重新解释相同项目上下文的方法。两个工具使用相同的格式——一个包含 SKILL.md 的文件夹,里面存放指令和元数据,以及可选的脚本、参考资料和资产。Codex 在你用 $ 或 /skills 调用技能时运行它,或者在你的任务匹配技能描述时自行运行——这就是为什么一个精准、朴实的描述胜过一个聪明讨巧的描述。Claude Code 的做法相同,我在智能体技能一文中详细写过这个模式。
技能也是意图不再反复付出代价的地方。我在意图债务中论述过,智能体每次会话都是从零开始,它会用自信的猜测填补你意图中的任何空白。技能就是将意图外化写下的方式——约定、构建步骤、"我们不这么做是因为某次事故"——写一次,智能体每次运行都会读取。没有技能,循环每个周期都从零开始重新推导你的整个项目;有了技能,它会逐渐复利增长。
有一点要分清:技能是编写格式,插件是分发方式。当你想跨仓库分享技能或将几个技能打包在一起时,就将它们打包为插件。Codex 如此,Claude Code 亦然。
插件与连接器:让循环看见你的环境
一个只能看到文件系统的循环是一个微小的循环。连接器基于 MCP 构建,让智能体读取你的 issue 追踪器、查询数据库、访问 staging API、在 Slack 里发消息。Codex 和 Claude Code 都支持 MCP,所以你为一个工具写的连接器通常在另一个工具上也能直接使用。插件则将连接器和技能打包在一起,让你的队友一次安装你的整套设置,而不是凭记忆重建所有东西。
这就是"这是修复方案"的智能体与"自动开 PR、关联 Linear ticket、CI 通过后自动通知频道"的循环之间的区别。连接器是循环能够在你的实际环境中行动的原因,而不只是告诉你它如果能做到会做什么。
子智能体:创作者与审查者
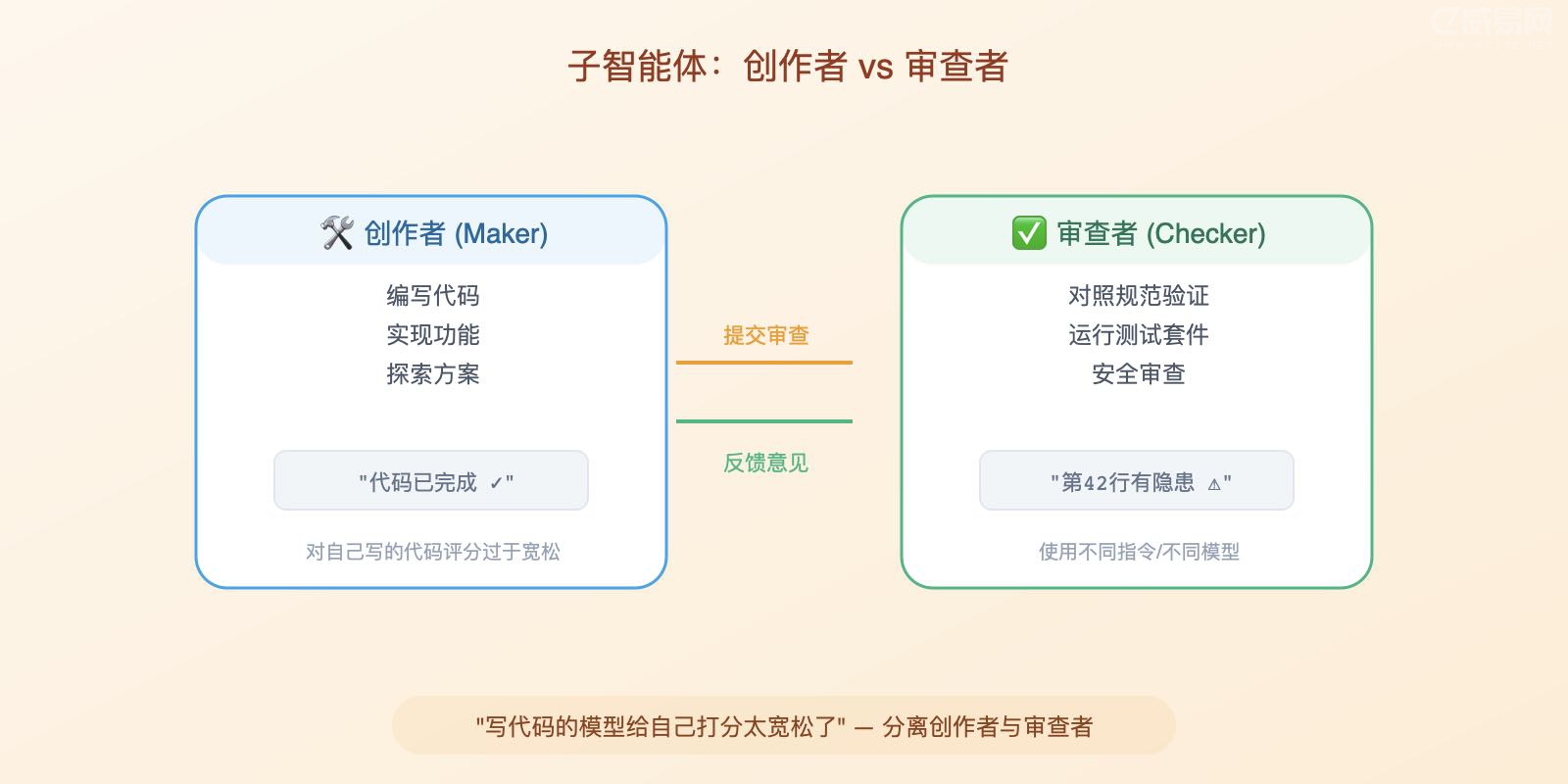
循环中最有用的结构性设计,远不止于此——将写代码的与检查代码的分开。写代码的模型对自己代码的评分过于宽容。一个拥有不同指令、有时甚至是不同模型的第二智能体,能捕获第一个智能体自我说服的那些问题。
Codex 只在你请求时才衍生子智能体,同时运行它们,然后将结果合并为一个答案。你可以在 .codex/agents/ 中以 TOML 文件定义自己的智能体——每个都有名称、描述、指令以及可选的模型和推理力度。这样你的安全审查者可以是一个在高推理力度下运行的强模型,而你的探索者可以是一个快速的只读型智能体。Claude Code 同样在 .claude/agents/ 中定义子智能体,并支持在它们之间传递工作的智能体团队。两者中常见的分工是:一个智能体探索,一个实现,一个对照规范验证。
我在两篇文章中已经论证过这一点:代码智能体交响乐和对抗性代码审查。这在循环中特别重要的原因是——循环在你不在的时候运行,所以一个你真正信任的验证者是你能够走开的唯一理由。子智能体确实会消耗更多 token,因为每个都有自己的模型和工具调用,所以把它们花在值得听取第二意见的地方。这基本上也是 Claude Code 的 /goal 在底层做的事情——一个全新的模型来决定循环是否完成,而不是执行工作的那个模型——创作者与审查者的分离被应用到了停止条件本身上。
把它们拼在一起:一个完整的循环
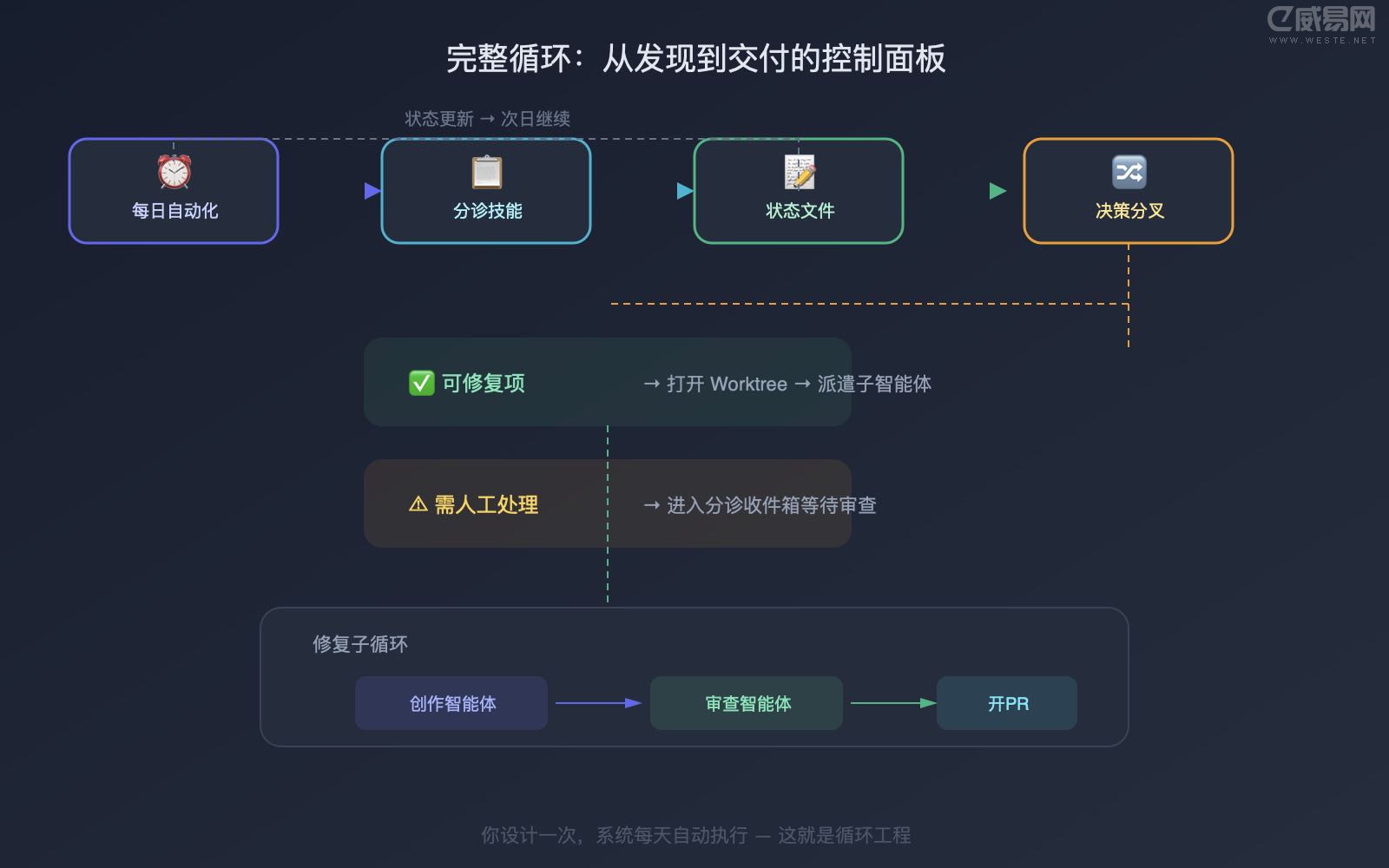
把这些粘合在一起,单个线程就变成了一块小型控制面板。以下是我一直使用的一种形态:
一个自动化每天早上在仓库上运行。它的提示词调用一个分诊技能,读取昨天的 CI 故障、开放 issue、最近的提交,并将发现写入一个 Markdown 文件或 Linear 看板。对于每个值得处理的发现,线程会打开一个隔离的工作树,派遣一个子智能体起草修复方案,第二个子智能体对照项目技能和现有测试审查该方案。
连接器让循环自动开 PR 和更新 ticket。任何循环无法处理的事情都会进入分诊收件箱等我处理。状态文件是整个系统的脊柱——它记住尝试过什么、通过了什么、还有什么未解决,这样第二天早上的运行就会从今天停止的地方继续。
看看你实际做了什么。你只设计了一次。你没有亲自提示这些步骤中的任何一个。这就是 Steinberger 所说的全部要点的实践。无论是 Codex 还是 Claude Code,这都是同一个循环,因为组件是一样的。
循环改变了工作,但没有消除你

循环改变了工作,但它没有将你从中删除。有三个问题实际上随着循环变得更好而变得更尖锐,而不是更容易。
验证仍然是你的责任。 一个无人值守运行的循环,也是一个无人值守犯错的循环。你将验证子智能体与创作者分离的全部原因,就是让循环说"完成了"有意义——即便如此,"完成"是一个声明,而不是一个证明。我一直在重复AI 时代的代码审查中的那句话:你的工作是交付你确认有效的代码。
你的理解力仍然会退化,如果你放任它的话。 循环交付你没写过的代码越快,"存在的代码"与"你真正理解的代码"之间的差距就越大。这就是理解力债务,一个顺畅的循环只会让它增长得更快——除非你阅读循环产出的东西。
舒适的姿态是危险的姿态。 当循环自己运行时,你很容易停止形成自己的观点,只是接受它返回的任何结果。我把这称为认知投降。当你带着判断力设计循环时,它是解药;当你为了逃避思考而设计循环时,它是催化剂——相同的动作,相反的结果。
结语:构建循环,但保持工程师身份
我认为这是对我们将要工作方式的预览。不过话说回来,如果我不亲自审查代码,或者完全依赖自动化循环来修复它,我的产品质量就会下降。我很可能会陷入一个向下的螺旋,不断把自己挖进更深的坑里。
话虽如此,尽管去建立你的循环吧,但别忘了直接向你的智能体写提示词也同样有效。关键在于找到正确的平衡。
循环也可能导致不同的结果,取决于你是谁。两个人可以构建完全相同的循环,却得到截然相反的结果。一个人用它在自己深入理解的工作上更快地推进;另一个人用它来完全回避理解工作。循环不知道其中的区别。你知道。
这正是循环设计比提示词工程更难——而非更容易——的原因。Cherny 的要点不是工作变简单了,而是杠杆点移动了。
构建循环。但请以一个打算继续做工程师的人的身份来构建它,而不是那个只会按下启动键的人。
原文:https://addyosmani.com/blog/loop-engineering/