2026年6月9日,Anthropic发布了Claude Fable 5。
照例,官方说它"超越了此前所有公开可用的模型"。这类话每次发布都会说,读者早已免疫。
但这一次,有一句话值得停下来认真想一想。

Thariq是Anthropic内部Claude Code团队的开发者,Fable 5发布当天他写道:
"以前我们检查Claude是否把活儿做对了——比如有没有偷懒、有没有出错。用了Fable 5之后,我检查的是Claude是否在做正确的事。"
"做对没有"和"做的对不对",表面上只是措辞的差异,背后却是人与AI协作关系的根本性转变。前者是执行层面的可靠性问题——你必须盯着它,因为它随时可能出错;后者是方向层面的对齐问题——执行它已经能自己搞定,你需要想清楚的是目标。
这篇文章想说的,正是这个转变——它在Fable 5的每一项能力里,都有具体的体现。
工程师不再是监工
先看一个最直接的例子。
Stripe在测试Fable 5时汇报:在一个5000万行的Ruby代码库里,Fable 5用一天时间完成了一次全库迁移。同样的工作,一个完整的工程师团队手动操作需要两个月以上。
数字本身已经足够震撼。但更值得关注的,是这件事背后的协作结构变了。
以往,把一项大型工程任务交给AI,工程师需要做的事情非常多:把任务拆解成足够小的片段,逐一下达指令,核查每段输出有没有出错,发现问题及时纠偏,再推进下一步。AI是一把需要人手持、反复校准的工具。
这一次,Stripe的工程师不需要做这些。他们只需要说清楚迁移目标,剩下的——选择路径、执行代码、从失败中恢复、推进到完成——Fable 5自己跑完了。
工程师从监工变成了出题人。
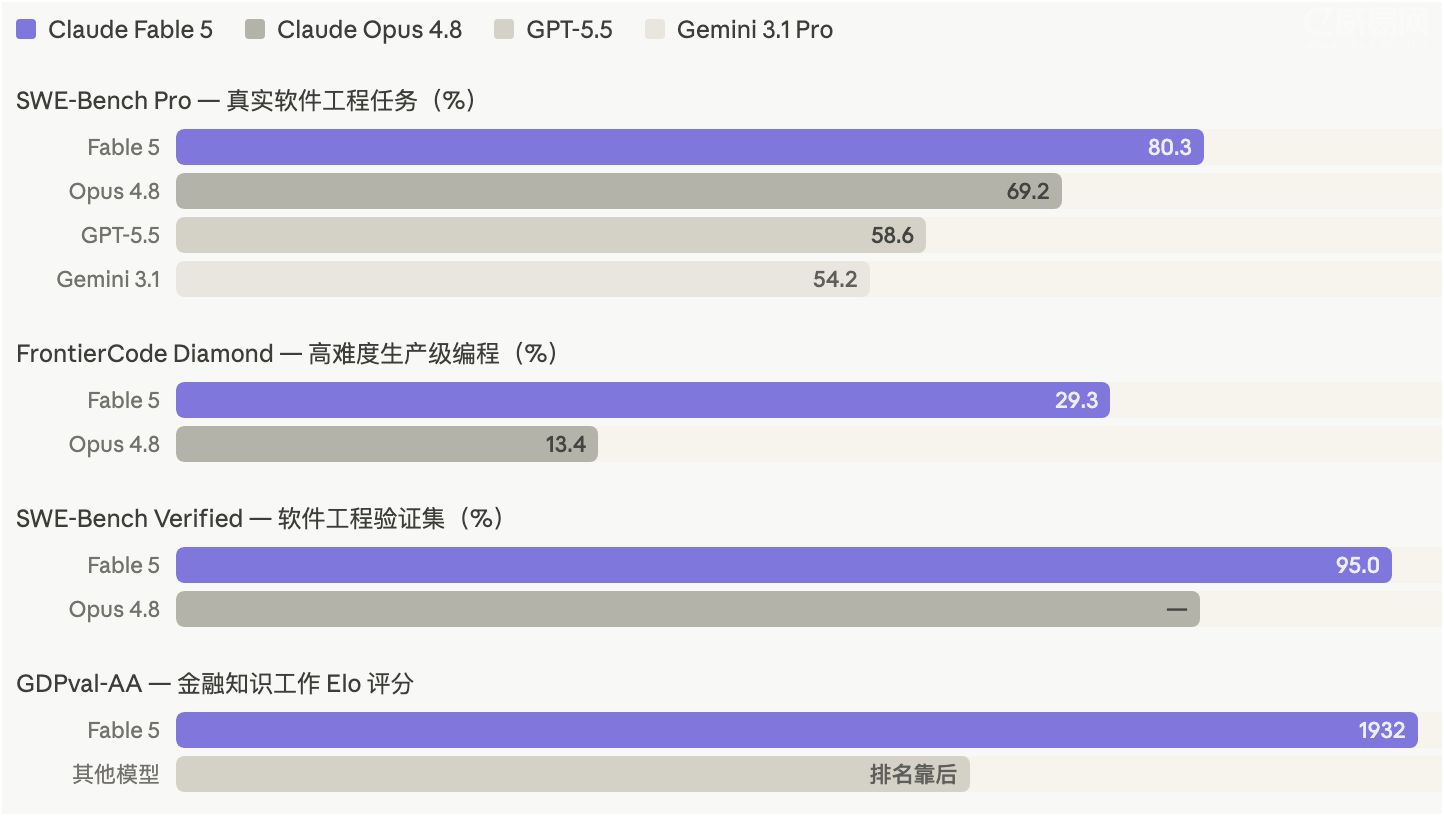
在编程基准测试上,这种变化也有数字印证。规律很清晰:任务越长、越复杂,Fable 5的领先幅度就越大。这不是一次均匀的能力提升,而是在"长时间自主执行"这件事上的跳变——恰恰是过去工程师必须亲自介入的那个环节。
性能对比:主要基准测试
| 基准测试 | 说明 | Fable 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| SWE-Bench Pro | 真实软件工程任务 | 80.3% | 69.2% | 58.6% | 54.2% |
| SWE-Bench Verified | 软件工程验证集 | 95.0% | — | — | — |
| FrontierCode Diamond | 高难度生产级编程 | 29.3% | 13.4% | — | — |
| GDPval-AA | 金融知识工作 Elo | 1932 | — | — | — |
| Agent 任务得分 | 多步骤工具编排 | 80.7 | — | — | — |
视觉任务:人从翻译者变成了审阅者
同样的逻辑,在视觉任务上也在发生。
以往,把一个截图交给AI,你需要告诉它:这里是导航栏、这里是按钮、这个颜色是主色调、这段代码对应这个交互……你是一个翻译者,把视觉信息转化成AI能理解的文字描述,然后它才能动手。
Fable 5之后,这个翻译的环节消失了。它可以直接从截图重建一个Web应用的完整源代码,无需任何额外的文字说明。用一个更极端的例子来说明:此前的Claude模型需要借助额外工具才能玩《Pokémon FireRed》,Fable 5用纯视觉输入通关了整个游戏——没有地图,没有辅助信息,只有原始的游戏画面。
人不再需要充当AI的眼睛。AI自己能看,能理解,能行动。
这意味着那些以视觉为主要载体的工作——界面设计的还原、图表数据的提取、复杂文档的解析——人的角色从"把视觉翻译给AI"变成了"审阅AI的理解结果是否符合意图"。这是一个本质不同的位置。
科研:AI从助手变成了独立的研究者
如果说工程和视觉的变化还在"执行层",那Fable 5在科学研究上的表现,触及的是更深的层次。
Anthropic内部的蛋白质设计团队用Mythos 5(与Fable 5底座相同)测试发现:在蛋白质设计的部分环节,AI已经可以在无人协助的情况下,独立完成一名技术熟练的科学家所承担的全部工作——选择结合位点、挑选和运行蛋白质设计工具、从失败中自主恢复。这一过程将药物设计的部分环节提速约十倍。
更值得关注的是另一项结果:在基因组学研究中,Mythos 5进行了超过一周的基本自主研究,整合了138个动物物种、数百万细胞的单细胞数据,设计并训练了一个自定义机器学习模型,最终性能超越了《Science》期刊上发表的一个近期模型——尽管体量只有那个模型的1/100。这项研究只有高层级的人类输入介入,具体路径由AI自行规划和执行。
科研人员在这里扮演的角色,不是逐步指导AI做实验,而是提出问题、设定方向,然后审阅AI带回来的结论。
这是一个过去只属于人类的位置:独立的研究者,而不是执行工具。
能力全景
经过上面三个方向的拆解,可以对Fable 5的能力做一个完整的概览。

| 能力方向 | 核心表现 | 对人的角色意味着什么 |
|---|---|---|
| 长任务自主编程 | 连续运行数小时,独立完成大型代码库迁移、重构、调试 | 工程师从监工变为出题人 |
| 视觉理解 | 从截图重建源代码;纯视觉通关《Pokémon FireRed》 | 人不再需要为AI"翻译"视觉信息 |
| 科学研究 | 独立完成蛋白质设计、基因组建模,产出可验证的新假说 | 研究者从指导者变为方向设定者 |
| 金融知识工作 | 文档推理、图表解读、根因分析全面领先,GDPval-AA Elo 排名第一 | 分析师的判断层级被整体上移 |
| 超长上下文 | 百万 token 输入,主动记笔记,任务越长优势越大 | 复杂项目不再需要人工拆解 |
| 工具调用与 Agent | Agent 得分 80.7,多步骤编排能力目前最强 | 工作流可以整体托管,而非逐步控制 |
规格参数
| 参数 | 数值 |
|---|---|
| 模型 ID | claude-fable-5 |
| 上下文窗口 | 1,000,000 tokens 输入 / 128K tokens 输出 |
| 输入定价 | $10 / 百万 tokens |
| 输出定价 | $50 / 百万 tokens |
| 对比 Opus 4.8 | 2× 价格,综合性能显著领先 |
| 对比 Mythos Preview | 同等能力,价格低 60% 以上 |
| 可用渠道 | claude.ai · API · Claude Code · GitHub Copilot · AWS · Google Cloud |
| 发布日期 | 2026 年 6 月 9 日 |
安全机制:能力强到需要"自我限制"
Fable 5的能力强到什么程度?强到Anthropic自己承认,不加限制不敢发布。
这倒不是修辞,而是事实。Fable 5的底座模型Mythos在今年4月首次亮相时,直接因为其在发现和利用软件漏洞方面的超凡能力,震惊了整个网络安全界。Anthropic拒绝公开发布,只向少数合作机构开放。
这一次,Fable 5能够公开发布,靠的是一套安全分类器。它会在网络安全、生物学、化学等高风险领域自动触发,将请求转交给Opus 4.8处理,而非直接拒绝。官方数据显示,平均不到5%的会话会触发这一机制,且用户会被告知。
这个设计本身,也折射出协作关系的新问题:当AI的自主执行能力强到这个程度,"让它做什么"的边界变得比"它能不能做到"更加重要。护栏的存在,是为了确保人在方向上的把控权不会因为能力的过剩而失效。
定价:怎么用,比用多少更重要
Fable 5的定价是每百万输出token 50美元,大约是Opus 4.8的两倍。但比此前受限开放的Mythos Preview便宜了60%以上。
贵还是不贵,取决于你用它做什么。
Stripe用一天替代了一个团队两个月的工作。有开发者用一句话指令和30美元生成了一个可玩的Minecraft克隆。如果任务是这个量级的,价格并不是障碍。
但如果把Fable 5用在所有场景、包括简单的日常查询,成本会迅速失控。Anthropic也意识到了这一点,同步发布了advisor工具,思路是让Haiku、Sonnet这类便宜的模型处理日常工作,只在关键决策和复杂任务上调用Fable 5——让最强的模型出现在真正需要它的地方。
这其实是"想清楚让它做什么"的另一个维度:不只是方向的对齐,也包括资源的对齐。知道什么时候该用Fable 5,和知道让Fable 5做什么,同样重要。
这个转变,对你意味着什么
Fable 5带来的不是一次效率提升,而是一次角色重新定义。
工程师不再需要把任务切碎、逐段核查;研究者不再需要手把手指导AI做实验;视觉工作者不再需要把截图翻译给AI看。那些原本属于"人盯着AI"的工作,正在转移给AI自己处理。
人被推到了一个新的位置:不是监工,而是出题人和决策者。这个位置要求的能力,不是更快的执行,而是更清晰的判断——对目标的判断、对方向的判断、对"什么值得做"的判断。
Thariq的那句话,说的其实不只是他自己的工作流程变化。它描述的,是人与AI协作关系里,人这一侧应该往哪里移动。
这个移动,现在已经开始了。