微信开放了小程序 AI 开发模式(目前还在内测),让你的小程序可以通过 AI 对话来完成用户操作。用户不再需要点来点去,直接用自然语言告诉 AI 想干什么,AI 会自动调用你封装好的能力来完成任务。
这篇文章基于微信官方的 ai-mode-demo 项目,讲清楚这套东西到底是怎么回事、怎么接入。
先搞清楚几个概念
什么是 SKILL
SKILL 是你对小程序某个业务场景的完整封装。一个小程序可以有多个 SKILL,比如"点单"是一个 SKILL,"查订单"是另一个 SKILL。每个 SKILL 包含三个东西:
- SKILL.md:告诉 AI 这个 SKILL 是干什么的,业务流程是什么,什么时候该调什么接口
- mcp.json:声明这个 SKILL 有哪些接口可以调用,每个接口的输入输出是什么
- index.js:实际的接口实现代码
什么是原子接口
原子接口就是最小的业务执行单元。比如"获取推荐饮品"是一个原子接口,"选择饮品规格"是另一个。每个原子接口做一件事,输入输出都是标准化的。
什么是原子组件
原子组件是原子接口的可视化展示。接口返回的数据通过组件渲染成 GUI 卡片,显示在 AI 对话流里。用户看到的不是一堆文字,而是一张张可以点击的卡片。
小程序 MCP 和标准 MCP 的区别
标准 MCP(Model Context Protocol)是一个通用协议,定义了 AI 模型和外部工具交互的方式。小程序 MCP 是微信基于小程序特点做了适配的版本,你不需要从零实现 MCP 协议,只需要按规范封装好 SKILL,微信的 AI 引擎会自动完成推理和调用。
项目结构
以官方 Demo 为例,一个接入了 AI 开发模式的小程序项目结构是这样的:
├── app.js / app.json / app.wxss # 小程序全局配置 ├── pages/ # 主包页面 │ └── home/ # 首页 ├── skills/ # SKILL 独立分包 │ └── drink-skill/ # 一个完整的 SKILL │ ├── SKILL.md # 业务说明文档 │ ├── mcp.json # 接口声明 │ ├── index.js # 接口注册 │ ├── apis/ # 原子接口实现 │ │ ├── getRecommendedDrinks.js │ │ ├── searchDrinks.js │ │ ├── selectDrink.js │ │ ├── confirmSku.js │ │ └── ... │ ├── components/ # 原子组件 │ │ ├── recommended-drinks/ │ │ ├── drink-detail-card/ │ │ ├── order-confirm-card/ │ │ └── ... │ └── utils/ ├── packageDetail/ # 半屏页面分包 └── page-meta.json # 页面元数据
关键点:SKILL 是作为独立分包存在的,不是放在主包里。这很重要,因为 SKILL 的运行环境和普通小程序页面是隔离的。
第一步:申请开启 AI 开发模式
在以下两个入口之一申请:
- 网页端:微信公众平台 → 基础功能 → AI 能力 → 选择「开发模式」
- 小程序端:微信开发者助手 → 管理 → 微信 AI 管理 → 选择「开发模式」
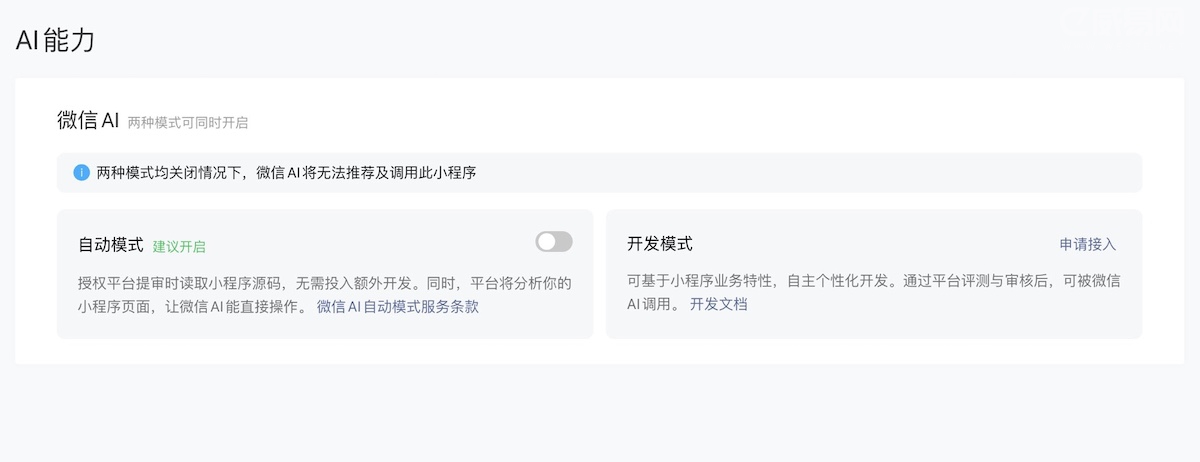
当前是内测阶段,需要等审核通过。
第二步:配置 app.json
在 app.json 中需要做两件事:声明 SKILL 分包和配置 agent 字段。
{
"pages": [
"pages/home/home"
],
"subPackages": [
{
"root": "skills",
"pages": [],
"independent": true
}
],
"agent": {
"skills": [
{
"name": "drink",
"description": "WeStoreCafe 点单场景:查询推荐饮品、选择规格、填写收货地址、下单支付",
"path": "skills/drink-skill"
}
],
"pageMetadata": "page-meta.json"
}
}
几个要点:
- skills 分包必须设置 "independent": true,因为 SKILL 运行在独立的 JS 环境中
- agent.skills 数组声明了你的小程序有哪些 SKILL,path 指向 SKILL 的目录
- pageMetadata 指向页面元数据文件,用于告诉 AI 有哪些页面以及它们是干什么的
第三步:编写 SKILL.md
SKILL.md 是写给 AI 看的文档,它决定了 AI 怎么理解和使用你的接口。这是整个接入中最关键的文件之一。
一个好的 SKILL.md 应该包含:
1. 业务流程图
用文字或 ASCII 图描述完整的业务流程,让 AI 知道用户的操作路径是什么:
用户意图 │ ├─ 模糊意图("想喝点什么")─→ getRecommendedDrinks → 推荐卡片 │ ├─ 明确关键词("拿铁")───→ searchDrinks → 搜索结果卡片 │ │ 用户点击卡片选择某款饮品 │ ↓ │ selectDrink → 饮品详情卡片 │ ↓ │ confirmSku → 订单确认卡片 │ ↓ │ payOrder → 支付成功卡片
2. 接口依赖关系表
列出每个接口的前置条件,让 AI 知道调用顺序:
| 接口 | 作用 | 前置条件 | |------|------|----------| | getRecommendedDrinks | 模糊意图时展示精选饮品 | — | | searchDrinks | 按关键词搜索饮品 | 用户提供了关键词 | | selectDrink | 查看饮品详情与规格 | 已有 drinkId | | confirmSku | 确认规格生成订单 | 已调 selectDrink | | payOrder | 发起支付 | 订单 status=confirmed |
3. 业务约束(铁律)
这部分特别重要,用来防止 AI 犯低级错误:
## 业务约束 ### 输出形态 - 所有成功返回的接口必须展示卡片,禁止以纯文本列出详情数据 ### 执行顺序 - payOrder 必须在调用成功后才能向用户宣布"支付成功" - confirmSku 必须在 selectDrink 成功后调用 ### 数据来源 - drinkId 必须来自上游接口返回的原值,禁止编造 - 所有枚举值必须使用英文,禁止使用中文 label
4. 用户意图分流
告诉 AI 什么样的用户输入应该触发哪个接口:
### 直接意图 - "想喝点什么" → getRecommendedDrinks - "来杯拿铁" → searchDrinks - "最近的门店" → getStoreStatus ### 意图分流规则 - 模糊表达 → getRecommendedDrinks - 具体品名 → searchDrinks - 歧义短语 → 先反问澄清,禁止猜测
第四步:编写 mcp.json
mcp.json 声明了 SKILL 中所有可用的接口及其输入输出格式。这是标准的 JSON Schema 格式。
{
"apis": [
{
"name": "getRecommendedDrinks",
"description": "获取推荐饮品列表。调用前置条件:用户表达想喝饮品但未指定具体商品名。",
"inputSchema": {
"type": "object",
"properties": {
"scenario": {
"type": "string",
"description": "使用场景。可选值:default/coffee/tea/warm",
"enum": ["default", "coffee", "tea", "warm"]
}
}
},
"outputSchema": {
"type": "object",
"properties": {
"items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"drinkId": { "type": "number" },
"name": { "type": "string" },
"price": { "type": "number" }
}
}
}
}
},
"_meta": {
"ui": {
"componentPath": "components/recommended-drinks/index"
}
}
}
],
"components": [
{
"path": "components/recommended-drinks/index",
"relatedPage": "/packageDetail/pages/more-drinks"
}
]
}
几个要点:
- name 必须和 index.js 中注册的接口名一致
- description 越详细越好,这是 AI 判断是否调用这个接口的主要依据
- _meta.ui.componentPath 指定了这个接口返回数据后用哪个组件来渲染
- components 数组声明了所有原子组件,relatedPage 指定了点击卡片后跳转的半屏页面
第五步:实现原子接口
每个原子接口是一个 async 函数,接收参数,返回标准化的结果对象。
// apis/getRecommendedDrinks.js
const { getCatalog } = require('../utils/storage.js')
async function getRecommendedDrinks({ scenario = 'default' } = {}) {
try {
const catalog = getCatalog()
const picked = catalog.slice(0, 3)
// structuredContent:AI 理解用的数据
const items = picked.map(d => ({
drinkId: d.id,
name: d.name,
price: d.price,
description: d.description
}))
return {
isError: false,
// content:给 AI 的指令,告诉它接下来该做什么
content: [{
type: 'text',
text: `已加载 ${picked.length} 款推荐饮品。接下来为用户展示推荐饮品卡片,禁止以纯文本列出详情。`
}],
// structuredContent:结构化数据,AI 可以理解
structuredContent: {
items,
total: picked.length,
hasMore: false
},
// _meta:组件渲染用,AI 不可见
_meta: {
viewItems: picked
}
}
} catch (err) {
return {
isError: true,
content: [{ type: 'text', text: `推荐失败:${err.message}` }]
}
}
}
module.exports = getRecommendedDrinks
返回对象的三个关键字段:
- content:给 AI 的文字指令。不是给用户看的,是告诉 AI "数据准备好了,接下来你应该展示卡片给用户"。好的 content 应该包含事实陈述和下一步动作指令。
- structuredContent:结构化数据,AI 可以理解并用来做推理。比如 AI 可以从这里读到 drinkId,用于后续调用 selectDrink。
- _meta:给组件渲染用的数据,AI 完全看不到。比如图片地址、完整的 schema 等,这些信息对 AI 没用,但组件渲染需要。
第六步:实现原子组件
原子组件就是普通的微信小程序组件,但它通过 wx.modelContext API 和 AI 对话流交互。
// components/recommended-drinks/index.js
Component({
data: {
items: [],
total: 0,
hasMore: false
},
lifetimes: {
created() {
// 获取 AI 上下文
this._modelCtx = wx.modelContext.getContext(this)
// 监听接口返回结果
this._modelCtx.on(wx.modelContext.NotificationType.Result, (data) => {
const result = data.result || {}
const sc = result.structuredContent || {}
const meta = result._meta || {}
// 优先用 _meta 的数据(含图片),fallback 到 structuredContent
const viewItems = meta.viewItems || sc.items || []
this.setData({
items: viewItems.slice(0, 3),
total: sc.total || viewItems.length
})
})
}
},
methods: {
onTapItem(e) {
const item = e.currentTarget.dataset.item
if (!item) return
// 用户点击后,向 AI 发送消息,触发下一个接口调用
this._modelCtx.sendFollowUpMessage({
content: [
{ type: 'text', text: `选择${item.name}` },
{
type: 'api/call',
data: {
name: 'selectDrink',
arguments: { drinkId: item.drinkId }
}
}
]
})
}
}
})
核心交互方式:
- 接收数据:通过 wx.modelContext.NotificationType.Result 监听接口返回的结果
- 触发下一步:通过 sendFollowUpMessage 向 AI 发送消息,可以附带接口调用指令(api/call),让 AI 自动调用下一个接口
- 打开半屏页面:通过 wx.modelContext.getViewContext(this).openDetailPage 打开关联的半屏页面
第七步:注册接口
在 SKILL 的 index.js 中,使用 wx.modelContext.createSkill 创建 SKILL 实例,然后逐个注册接口:
// skills/drink-skill/index.js
const getRecommendedDrinks = require('./apis/getRecommendedDrinks.js')
const searchDrinks = require('./apis/searchDrinks.js')
const selectDrink = require('./apis/selectDrink.js')
// ... 其他接口
// 创建 SKILL 实例,path 必须和 app.json 中的配置一致
const skill = wx.modelContext.createSkill('skills/drink-skill')
// 注册接口,name 必须和 mcp.json 中声明的一致
skill.registerAPI('getRecommendedDrinks', getRecommendedDrinks)
skill.registerAPI('searchDrinks', searchDrinks)
skill.registerAPI('selectDrink', selectDrink)
// ... 注册其他接口
完整业务流程示例
以"用户想喝杯咖啡"为例,走一遍完整流程:
- 用户说:"想喝点什么"
- AI 识别意图:模糊意图,调用 getRecommendedDrinks
- 接口返回:3 款推荐饮品的结构化数据
- 组件渲染:推荐饮品卡片显示在对话流中
- 用户点击:选了一杯拿铁
- 组件触发:sendFollowUpMessage 携带 drinkId 调用 selectDrink
- 接口返回:饮品详情和可选规格
- 组件渲染:饮品详情卡片,用户可以选温度、糖度、杯型
- 用户点击:"直接下单"
- 组件触发:调用 confirmSku,生成订单确认卡片
- 用户确认:补充地址后点击"确认下单"
- AI 调用:payOrder,完成支付
- 组件渲染:支付成功卡片
整个过程中,用户只需要用自然语言表达意图,然后在卡片上点击确认,AI 会自动处理所有中间步骤。
开发调试
- 下载安装 微信开发者工具(需要 Nightly Electron Build 最新版本)
- 导入项目后,把 appid 改成你申请了 AI 开发模式内测权限的 appid
- 编译运行,通过 AI 对话界面测试
一些踩坑点
- SKILL 运行环境是独立的:不能直接访问小程序的全局变量,数据共享要通过 wx.setStorageSync / wx.getStorageSync
- content 字段很重要:不要随便写,它直接影响 AI 的行为。好的 content 应该告诉 AI "数据是什么"和"接下来该做什么"
- 禁止编造 ID:所有 drinkId、orderId 必须来自上游接口的返回值,绝对不能从用户语言中推断
- 枚举值用英文:规格选择必须用 ice、hot 这样的英文枚举,不能用"冰的"、"热的"
- 先展示卡片,再等用户操作:不要让 AI 跳过卡片展示直接调用下一个接口
- 支付成功前不要宣布结果:payOrder 没返回成功之前,AI 不能告诉用户"已支付成功"
总结
接入微信小程序 AI 开发模式的核心工作就是三件事:
- 写好 SKILL.md:让 AI 理解你的业务流程和约束
- 声明好 mcp.json:让 AI 知道有哪些接口可以调用
- 实现好接口和组件:做好数据处理和 UI 渲染
本质上就是把你的小程序业务抽象成 AI 可以理解和调用的标准化能力。做好了这一步,用户就可以通过自然语言对话来使用你的小程序功能,不需要再一层层点菜单了。
官方 Demo 仓库:github.com/wechat-miniprogram/ai-mode-demo