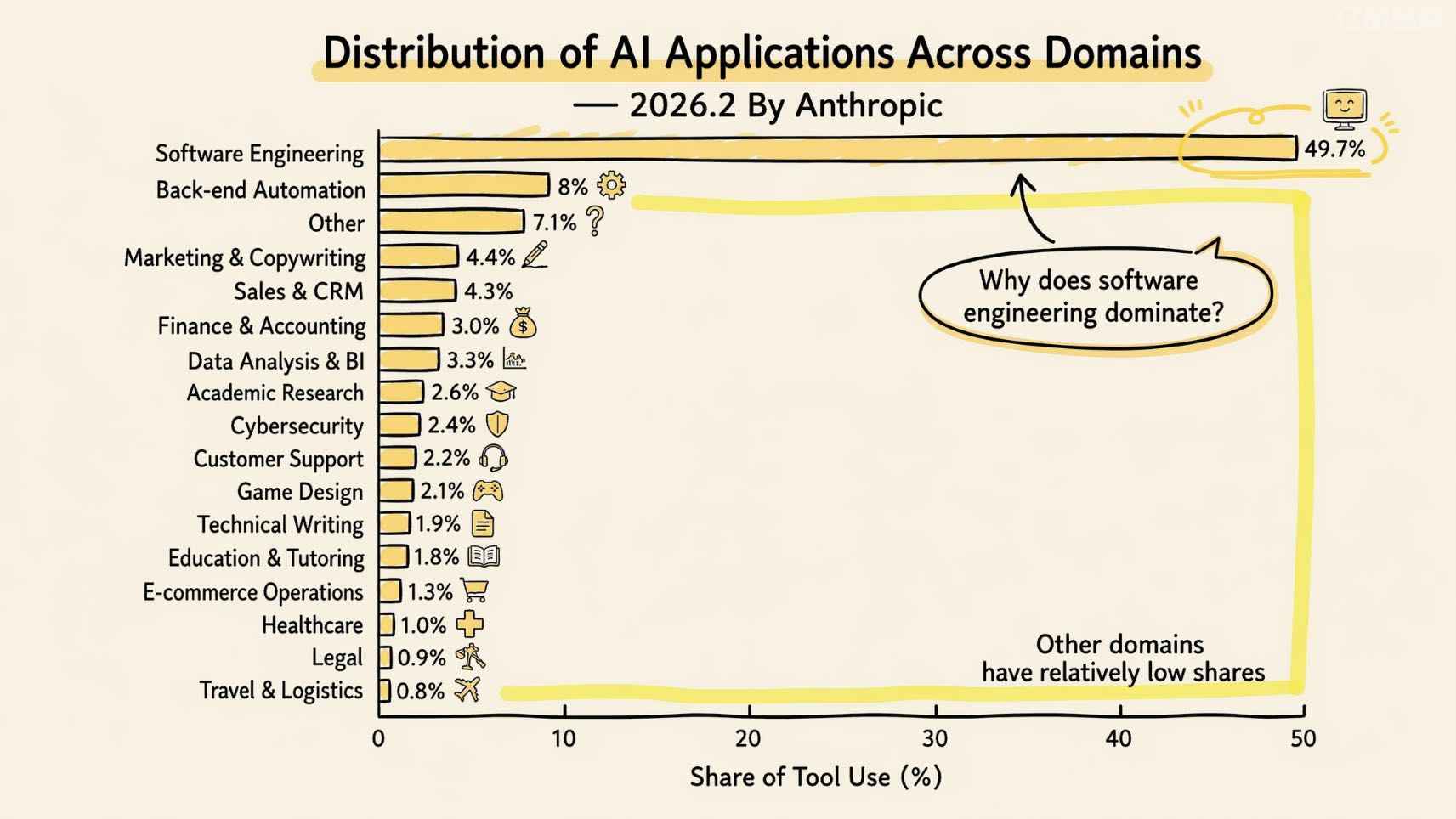
2026 年初,Anthropic 发布了一份平台调用数据报告。软件工程行业占了 AI Agent 使用量的 49.7%——接近一半。
这个数字乍一看挺正常,但仔细想想会觉得奇怪:写代码真的比看病、管仓库、做财务更需要 AI 吗?显然不是。真正的原因藏在另一个地方。
程序员赢在"起跑线"上
程序员天生就活在数字世界里。需求文档、设计稿、代码、Bug 列表、日志——全都已经在线上了。Agent 接进来,能"看见"的东西是完整的。它不需要额外做什么,就能理解上下文,直接干活。
换句话说,AI 编程能火起来,不是因为"代码特别适合 AI",而是因为程序员的工作环境刚好是数字化程度最高的那种。
但换个场景试试。
一个超市管理 Agent,它不知道货架有没有空,不知道价签标没标错,不知道隔壁门店今天在搞促销,也不知道今天的生鲜为什么损耗率突然飙高。就算背后接的是全世界最强的模型,它也做不出靠谱的决策。因为它"看不见"真实发生的事情。
这不是模型能力的问题,是 Agent 压根没有"眼睛"。
第一个坑:信息太碎,Agent 看不全
不管是人还是 Agent,做判断的前提是能观察到足够的信息。信息缺了一块,很多问题就从"难"变成了"不可能"。
AI Coding 之所以能跑通,是因为它的信息环境天然就是完整的。而很多行业的 Agent 只能看到一小片数字化切面——比如只有一个 ERP 系统里的几张表,其他全靠猜。
所以要让 Agent 进入真实业务场景,第一步不是调 Prompt、加技能、优化记忆——而是先解决"看得见"的问题。
阿里云的 EventHouse 团队给出了三种方式:
- 主动轮询:持续监控数据源,有变化就抓过来。
- 事件订阅:业务事件发生时主动推送给 Agent,不用它自己去找。
- 挂载查询:海量历史数据不搬过来,Agent 需要的时候再去查,类似挂载一块硬盘。
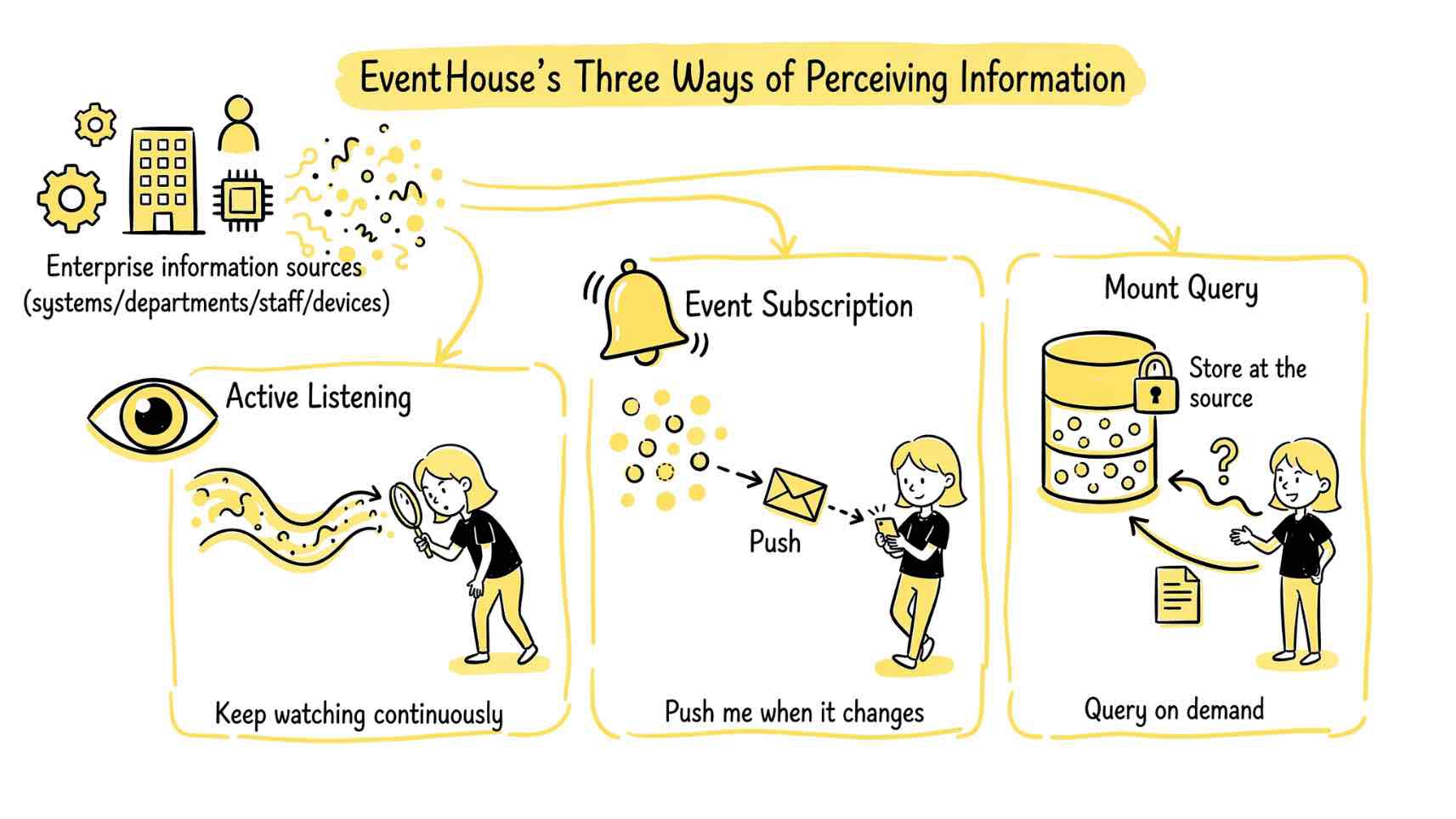
三种方式解决的是同一个问题:让 Agent 从"看一张静态快照"变成"持续感知业务动态"。
第二个坑:信息太多,反而更迷茫
你可能会想,那把所有数据都塞给 Agent 不就行了?
不行。这就像把整个图书馆的书全堆在你面前,但没有目录、没有索引。每次要找东西都得一本一本翻,效率低不说,还经常找错。
更麻烦的是:很多信息 Agent 虽然"理论上能访问",但它不知道自己能访问。比如接了一个数据库的 MCP,里面有一百张表,Agent 等到用户提问了才临时去翻表结构、拼查询语句——这跟考试前临时抱佛脚差不多,又慢又容易出错。
所以 Agent 需要的不是更多信息,而是一套"图书目录系统":提前知道有哪些信息、每类信息是什么意思、需要的时候去哪里找、优先级怎么排。
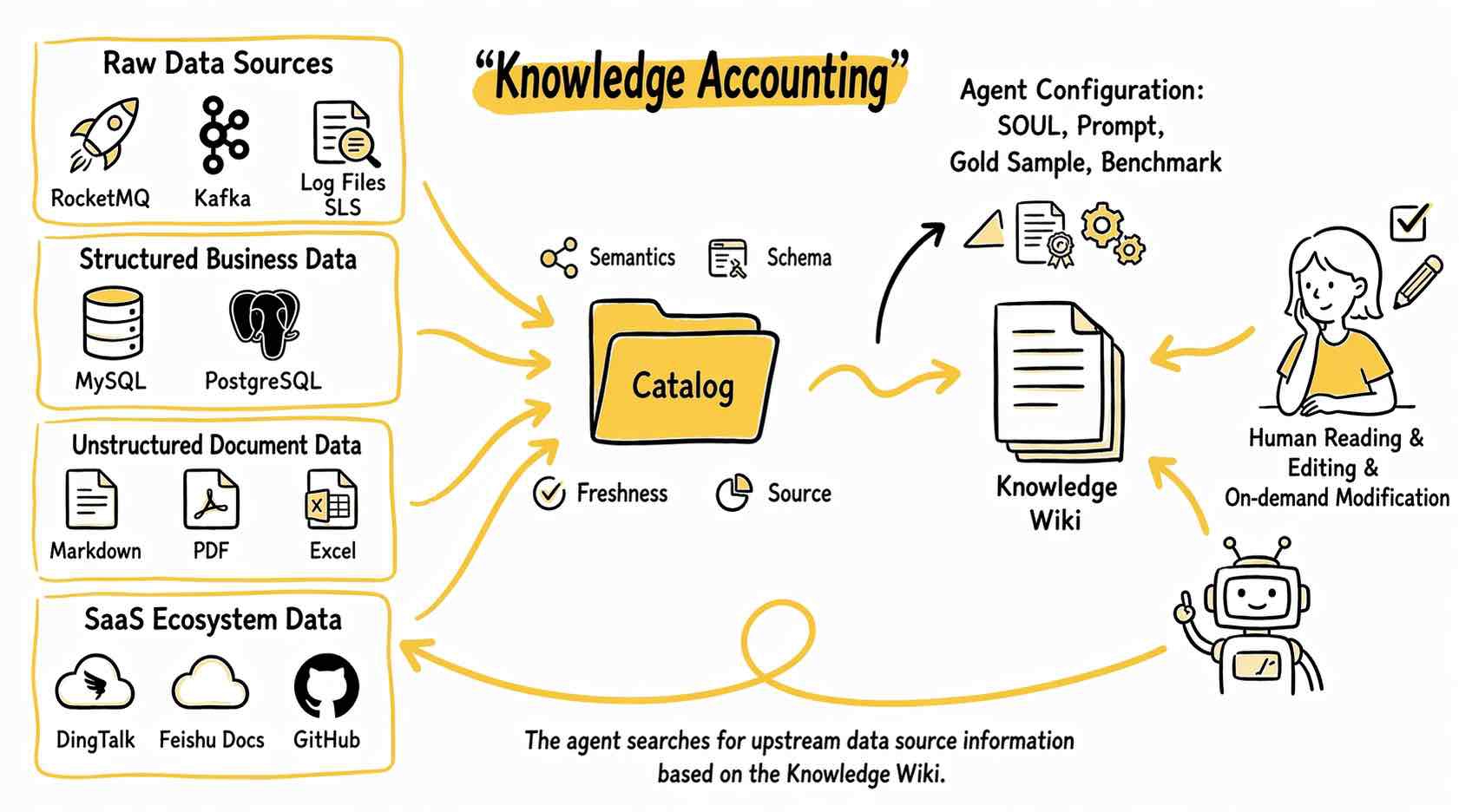
EventHouse 的做法是建一个统一目录(Catalog),把 Agent 能用到的信息资产都登记在册,包括数据的语义、结构、新鲜度、来源和关联关系。Agent 不用临时去摸索,目录里写得清清楚楚。
第三个坑:有数据不等于有判断力
有了目录,Agent 能找到信息了,但它就真的会用了吗?
不一定。一个人拥有整个图书馆,不代表他有判断力。信息要变成知识,才能真正指导行动。
这里有一个经典模型叫 DIKW——数据、信息、知识、智慧。简单说:
- 数据:原始记录,比如"今天卖了 300 箱牛奶"。
- 信息:加上背景和结构,比如"今天卖了 300 箱,比昨天多了 50 箱"。
- 知识:提炼出规则和方法,比如"周末销量通常比工作日高 30%,备货量要相应调整"。
- 智慧:在复杂情况下综合判断,比如"虽然周末销量高,但下周一有大促活动,备货量还要再加"。
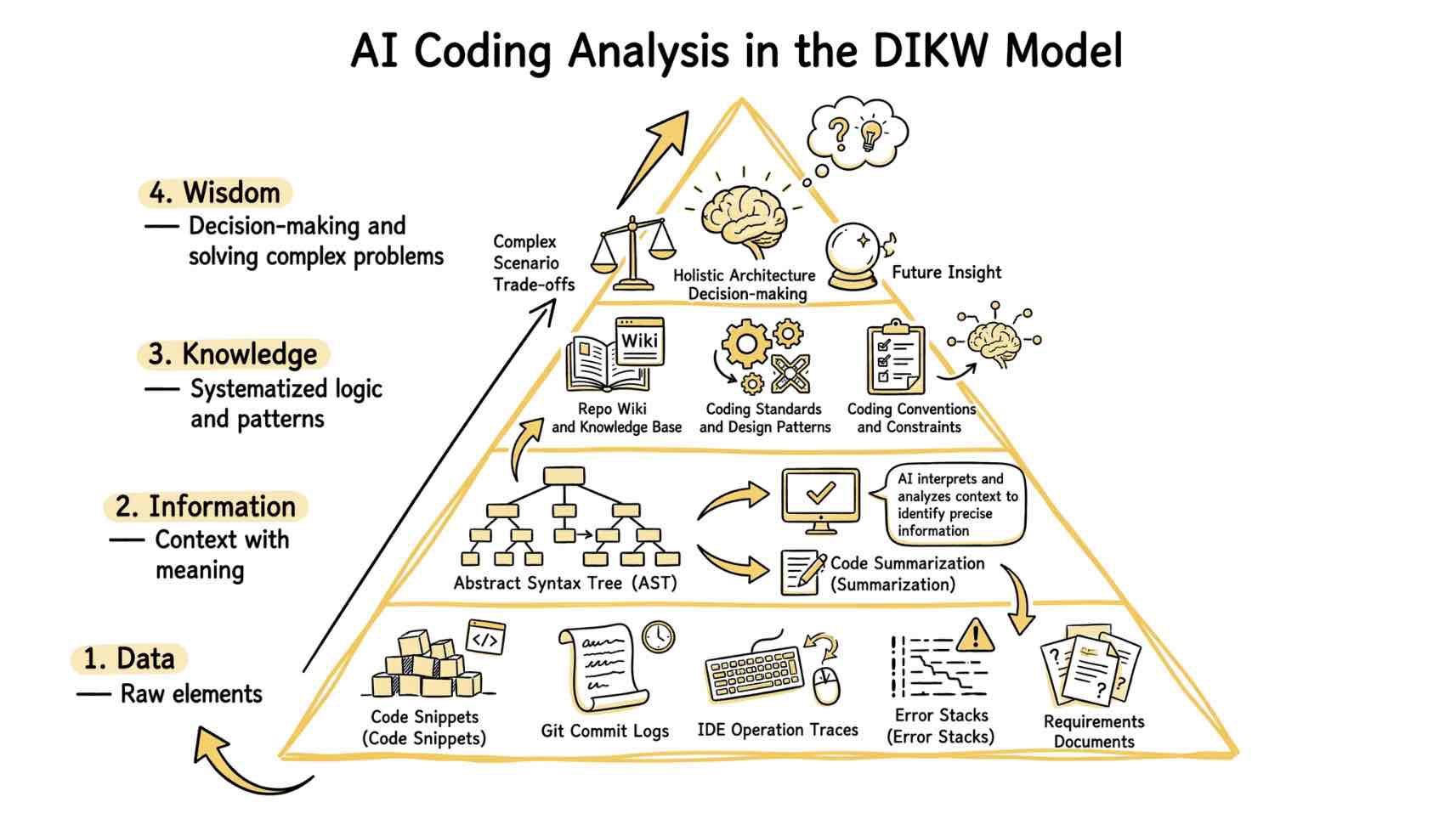
大多数 Agent 停留在"数据"和"信息"这层,还没摸到"知识"的边。
EventHouse 的做法是从两个方向帮 Agent 构建知识:一方面基于数据定义和语义信息,另一方面结合客户给 Agent 设定的角色、Prompt、标杆样本等内容,最终组织成一份可读、可审查、可迭代的"知识手册"。
这份手册最关键的地方在于:人和 Agent 之间能形成"知识对账"机制——人类专家可以审查 Agent 对数据的理解是不是对的,而不是把所有逻辑都藏在黑箱里。
第四个坑:知识更新了,但没人管发布
Agent 的知识不是一成不变的。数据源会变,表结构会改,客户会调整 Agent 的角色和目标,运行过程中积累的反馈也会越来越多。这些都在推动 Agent 的知识不断演进。
问题来了:新的知识手册生成之后,能直接上线吗?
软件工程领域有一条铁律:大量生产事故都跟"变更"有关。到了 AI 应用时代,这个规律没消失,只是变更的对象从代码、配置、基础设施,变成了 Prompt、知识手册、工具插件、模型能力和行为策略。
变了的东西不同,但对稳定性的要求没变。
企业级 Agent 同样需要一套完整的变更管理机制:上线前做回归测试,上线时灰度对比新旧版本,上线后发现问题能快速回滚。EventHouse 借鉴了 CI/CD 的思路,把一次 Agent 更新封装成一个可管理的"制品包",支持基准回归、蓝绿部署和版本回滚。
这一步的意义不只是"让 Agent 能持续更新",而是让更新本身变得可控、可验证、可恢复。
最后一个问题:接入门槛太高
回到前面说的四件事——多源信息感知、统一目录、知识手册、变更管理——它们本质上都在服务两个目标:简单、可靠。
为什么这两个词这么重要?有一个很好的类比:电的历史。
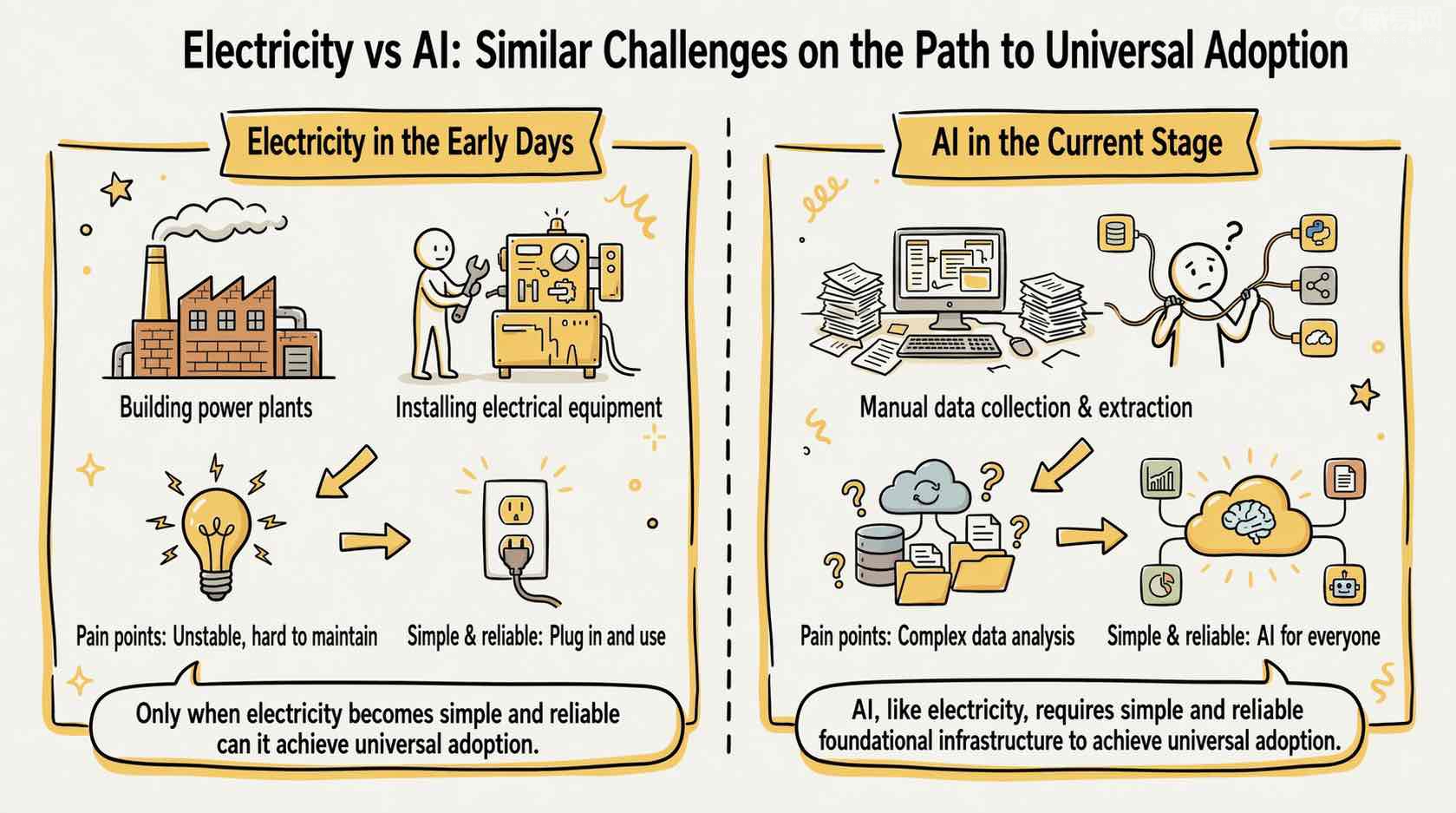
电刚发明的时候,不是每个工厂都能马上用。问题不是电没有价值,而是接入门槛太高:企业得自己买发电机、配维护人员、改造厂房布局、还得扛住供电不稳定的威胁。直到电网成为统一基础设施,工厂只需要一个标准插座就能获得稳定电力,电气化才真正从少数人的能力变成了整个行业的标配。
今天的 AI Agent 正处于类似阶段。很多企业不缺建 Agent 的意愿,缺的是长期投入数据整合、语义对齐、架构选型、变更管理和运维保障的能力。如果一套能力只有少数 AI 原生团队能掌握,那就不算真正的普惠。只有当 Agent 接入业务世界变得像插上电网一样低门槛、标准化、可持续,AI 才能真正进入千行百业。
说到底,拼的是"上下文供给"
下半场的竞争不只是模型参数和推理能力的比拼,更是谁能以更低成本、更高可靠性,持续把真实世界准确地带入数字系统。
从软件工程享受的"数字红利",到传统行业仍然缺失的"上下文基础设施",企业级 Agent 的真正分水岭,正在从模型能力转向环境能力。
谁能构建起多源、实时、可信、可治理的上下文供给体系,谁就更有可能把 Agent 从"Demo 级"带到"生产级"。
而那些还在用"模型不够强"来解释 Agent 落不了地的人,可能从一开始就找错了方向。