6 月 2 号凌晨,通义千问团队在 X 上连发了四条推文,宣布 Qwen3.7-Plus 上线。
这玩意儿的核心就一句话:一个模型,既看图又看文字,还能自己操作电脑。 阿里官方给的 slogan 是 "One model. Sees, thinks, codes, acts." 挺直白的。
之前做 Agent,视觉和语言基本是两条腿各走各的。你看图用视觉模型,写代码用语言模型,操作界面又要再套一层。Qwen3.7-Plus 的卖点就是把这些揉到一个模型里。
它到底能干什么
按官方列的四个方向:
- GUI 和命令行都能操作,看图和看文字来回切
- 写代码、当生产力助手
- 视觉 Agent——看懂屏幕上的东西、推理、找东西
- 适配各种 Agent 框架,不是绑死在某一个平台上的
说白了,就是想让一个模型把 Agent 活儿全包了,不用拼凑。
成绩怎么样
阿里这次把基准测试的数据全晒出来了。先看文本和编码这块:
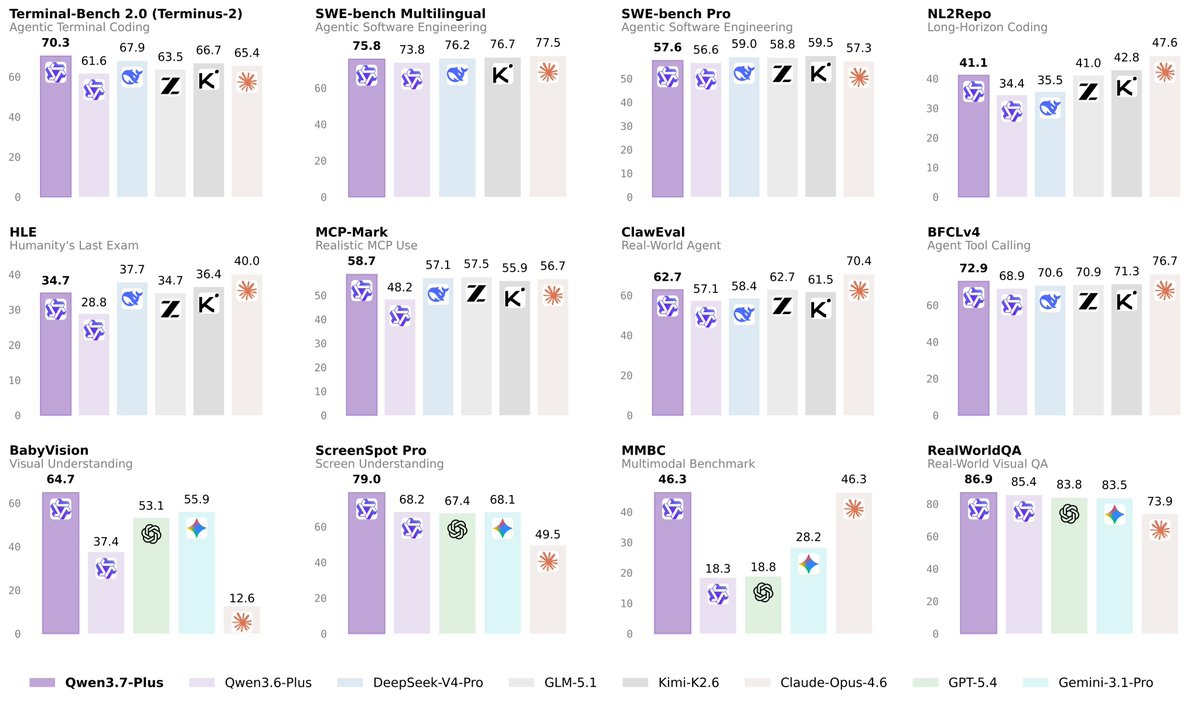
几个关键数字:
- SWE-bench Multilingual 75.8 —— 多语言编程任务,这个分数比 Claude-Opus-4-6 的 63.5 和 GPT-5.4 的 66.7 都要高
- SWE-bench Pro 57.6 —— 高级编程任务,超过了 Opus 的 56.6 和 GPT-5.4 的 56.7
- LiveCodeBench v6 72.9 —— 在线编程能力,和 Opus 的 72.2 差不多
- Terminal-Bench 2.0 70.3 —— 终端操作能力,比 Opus 的 63.5 高出一截
编码这块确实打得不差。
再看视觉和 GUI 理解:
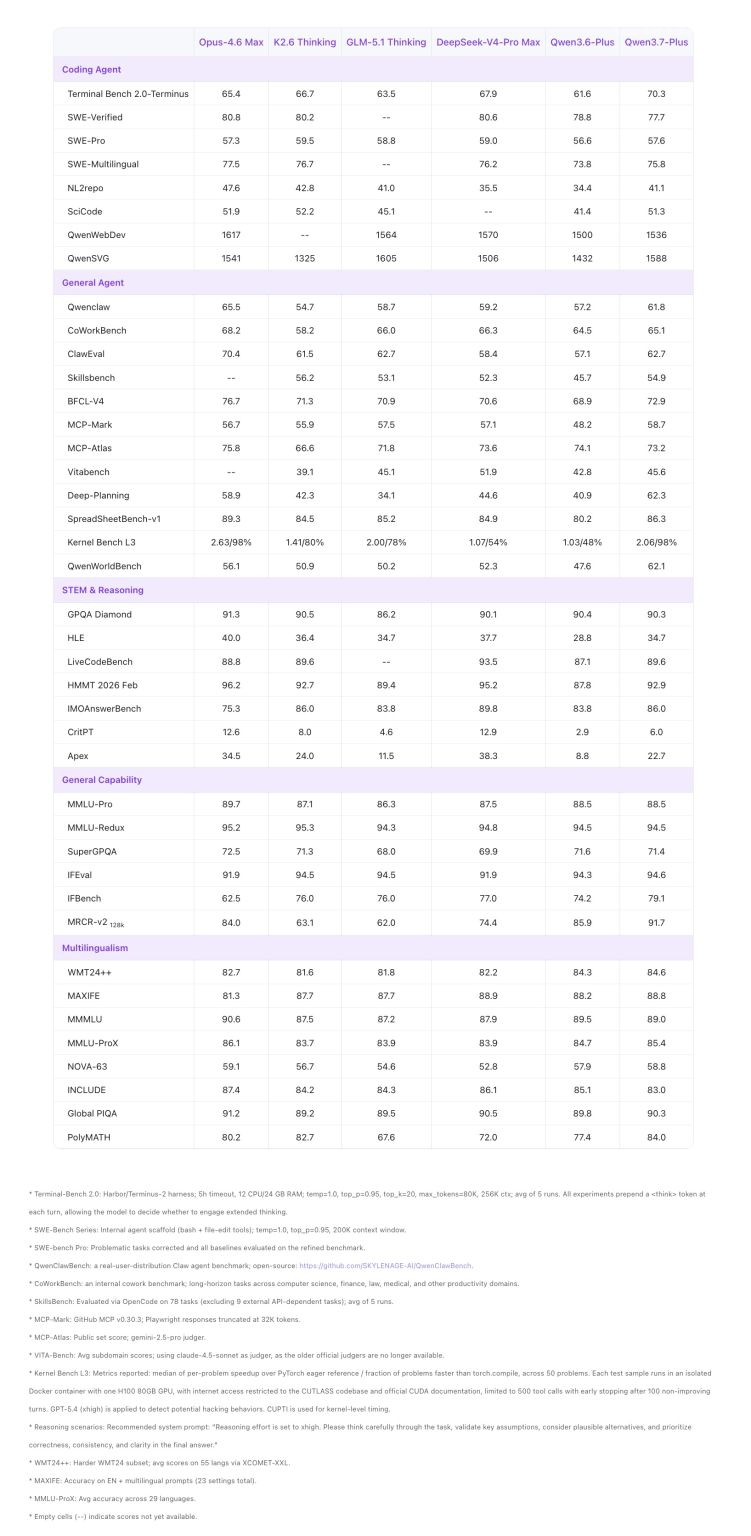
ScreenSpot Pro 79.0 这个分数值得注意——这个测的是 GUI 元素识别和定位能力,也就是"看屏幕截图然后找到该点的按钮在哪"这种活儿。Qwen3.7-Plus 在这项上超过了所有竞品。
BabyVision 64.7、MMBC 46.3、RealWorldQA 86.9,都是视觉理解相关的基准。
综合来看这 12 个基准测试的柱状图:
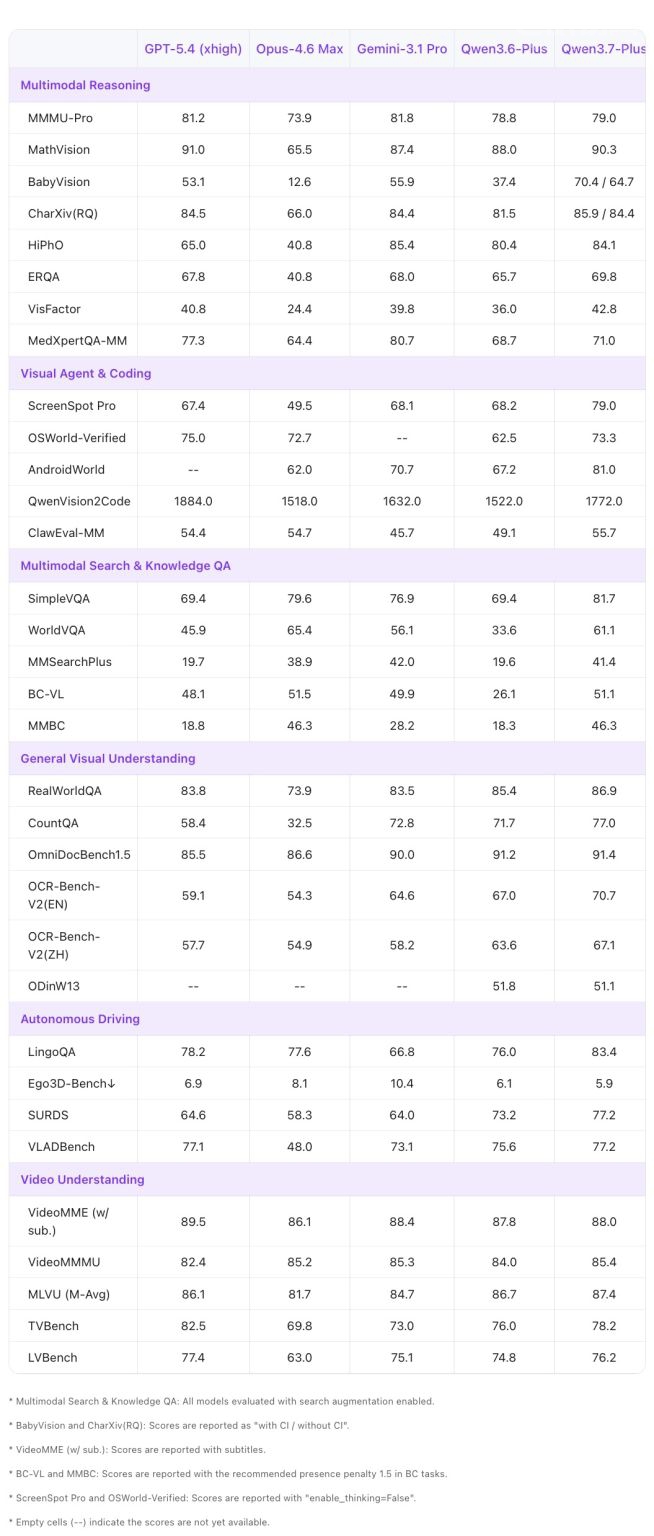
紫色柱子就是 Qwen3.7-Plus,在编码和 Agent 任务上基本是领先的,视觉部分有胜有负。
说实话,别太迷信基准
基准测试看看就好。跑分高不代表你实际用起来就好用。SWE-bench 上的高分说明模型在标准化的编程任务上很强,但真实项目里的复杂工作流完全是另一回事。
不过至少可以确定一点:Qwen3.7-Plus 在 Agent 任务上的能力确实上了一个台阶。如果你在用通义千问的生态,这个升级是值得关注的。