5月27日,小米MiMo V2.5系列API价格正式生效,最高降幅99%。几天前,DeepSeek也把V4-Pro的75%折扣从限时活动改成了永久定价。两家公司的Pro版输出价格都锁定在每百万Token 6元,缓存命中输入价格都是0.025元。
大多数报道把这叫"价格战"。但价格战是补贴换市场,烧的是投资人的钱。DeepSeek和MiMo的情况不太一样——它们降价的底气来自架构本身的改变,推理成本从根上就降下来了。
DeepSeek V4做了什么
传统Transformer在处理长上下文时有个致命问题:KV Cache。每一个Token都要存一份Key-Value对,上下文拉到100万Token,光缓存就能把一张GPU的显存吃满。DeepSeek V4的解法是搞了一套混合注意力架构,两种机制交替使用。
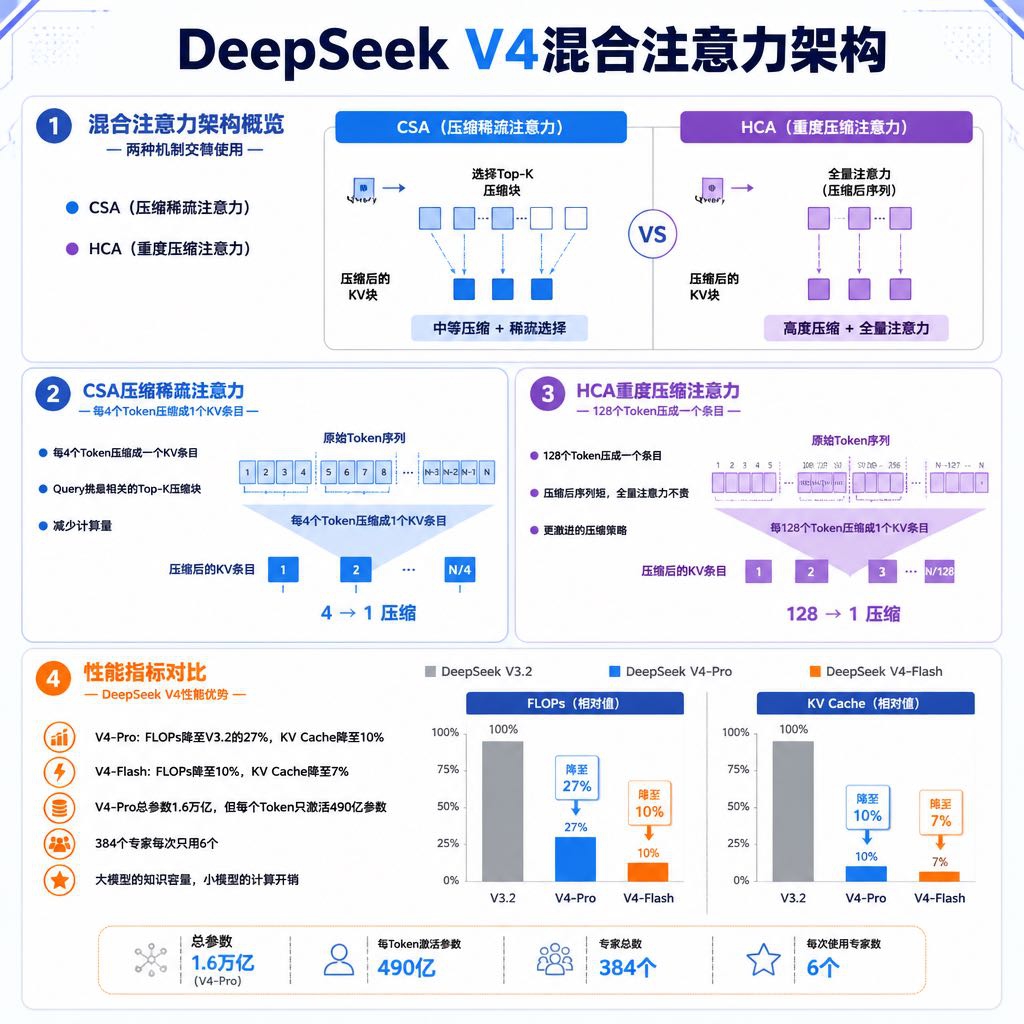
第一种叫CSA(压缩稀疏注意力),把每4个Token压缩成一个KV条目,然后每个Query只挑最相关的Top-K压缩块来算。第二种叫HCA(重度压缩注意力),更激进,128个Token压成一个条目,在压缩后的序列上跑全量注意力。因为压缩后的序列足够短,全量注意力也不贵。
效果很直接:在100万Token上下文下,V4-Pro的单Token推理FLOPs只有V3.2的27%,KV Cache只需要V3.2的10%。V4-Flash更夸张,分别压到10%和7%。
再加上MoE架构,V4-Pro总参数1.6万亿,但每个Token只激活490亿参数。384个专家里每次只用6个。大模型的知识容量,小模型的计算开销。
所以DeepSeek敢把价格定在GPT-5.5的十二分之一、Claude Opus 4.7的十九分之一,不是因为亏得起,是因为跑同样的任务,它消耗的算力确实就是那么多。
MiMo走了一条不同的路
小米的技术路线和DeepSeek不一样,但结果相似。MiMo团队基于SGLang框架做了HiCache优化,专门解决KV Cache在GPU显存、CPU内存和SSD之间的数据搬运问题。优化后数据搬运量降到之前的七分之一,可缓存的Token数量扩大了5倍。

同时MiMo还搞了一个叫HySparse的混合稀疏注意力架构。思路是49层模型里只保留5层全量注意力,剩下的用稀疏注意力替代。实验结果显示模型能力不降反升,KV Cache存储降低了接近10倍。
再加上专家并行优化和输入长度分桶策略,集群吞吐能力上来了,单Token的边际成本就下去了。MiMo标准版输出价格压到每百万Token 2元,比DeepSeek还低。
这跟以前的"价格战"不一样
2024年那波大模型降价,很多是补贴逻辑——先把价格砸下来抢用户,等市场格局定了再涨价。这次不一样。DeepSeek和MiMo的降价都是永久性的,因为成本结构真的变了。
当你的注意力机制物理上就处理更少的FLOPs,缓存占用物理上就更小的内存,服务成本在结构上就是更低的。价格跟着成本曲线走,不需要补贴来撑。
这对行业的冲击比单纯的价格战更大。2026年以来,大部分大模型公司其实是在涨价的,有些涨幅高达463%。DeepSeek和MiMo反着来,而且不是赔本赚吆喝,是有技术支撑的定价。缺乏类似架构优化的厂商就很难跟——跟了亏钱,不跟丢用户。
开发者是最大受益者
对普通开发者来说,这些数字意味着什么?百万Token调用成本已经低于一通电话费。一个创业团队跑完整个MVP测试周期可能就花几块钱。AI原生应用的试错成本趋近于零。
大模型竞争的衡量标准正在从"谁的Benchmark分数高"变成"完成一个实际任务要花多少钱"。DeepSeek和MiMo把这个问题的答案拉到了一个很低的水平,其他家要么跟进,要么在性能上拉开足够大的差距来证明溢价的合理性。