DeepSeek V4 Pro 的 API 价格将从促销价变成长期价。几乎同一阶段,昇腾 950、A3 系列超节点和 DeepSeek V4 的适配消息,也把国产 AI 算力重新推到台前。
DeepSeek 官方 API 定价页显示,deepseek-v4-pro 目前执行 75% off。页面脚注写明,这轮促销将在 2026年5月31日 15:59 UTC 结束,结束后该模型 API 价格将正式调整为原价的四分之一。
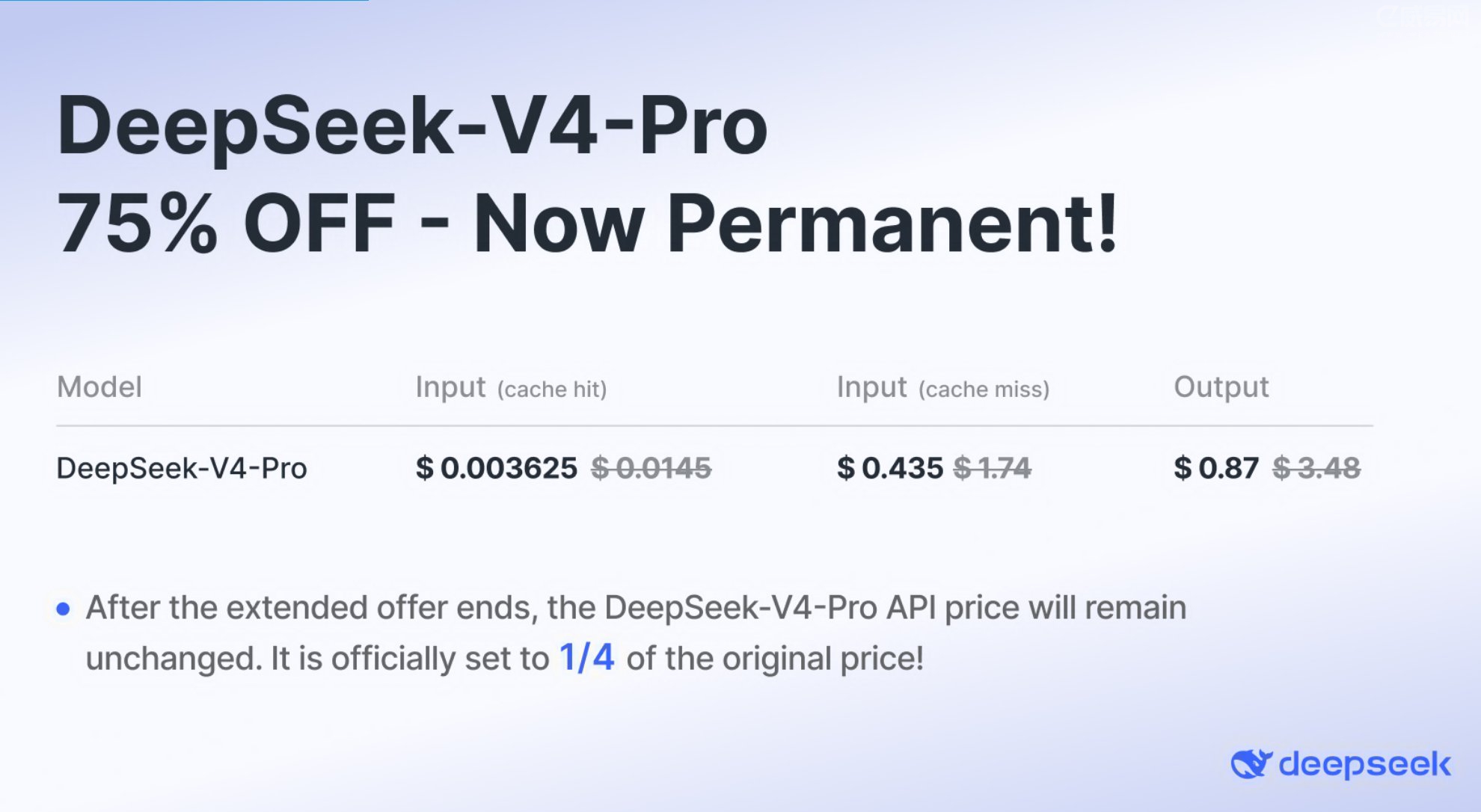
按当前页面价格,V4 Pro 缓存命中输入为每百万 tokens 0.003625 美元,缓存未命中输入为 0.435 美元,输出为 0.87 美元。对应原价分别为 0.0145 美元、1.74 美元和 3.48 美元。
| 计费项 | 调整后价格 | 原价 |
|---|---|---|
| 缓存命中输入 / 1M tokens | 0.003625 美元 | 0.0145 美元 |
| 缓存未命中输入 / 1M tokens | 0.435 美元 | 1.74 美元 |
| 输出 / 1M tokens | 0.87 美元 | 3.48 美元 |
这不是一次普通折扣。对长上下文、代码 Agent、企业知识库和批量自动化任务来说,API 单价会直接改变应用能不能长期跑起来。过去很多方案不是模型能力不够,而是账单太重。V4 Pro 把价格压到这个位置后,开发者会重新计算上下文长度、调用频率和 Agent 流程的成本。
V4 Pro 先把长上下文成本打薄
DeepSeek-V4-Pro 模型卡显示,该模型支持 1M token 上下文,是 1.6T 总参数、49B 激活参数的 MoE 模型。它采用混合注意力架构,重点降低长上下文推理开销。
模型卡给出的数字很直接:在 1M token 场景下,V4 Pro 相比 DeepSeek-V3.2 只需要约 27% 的单 token 推理 FLOPs,KV cache 约为后者的 10%。长上下文服务里,KV cache 影响显存占用,也影响并发。这个成本被压下来,API 价格才有下探空间。
缓存命中输入价格尤其低。对长文档、代码仓库和历史对话场景来说,用户越能复用上下文,实际调用成本越低。DeepSeek 把这部分价格降下来,相当于鼓励开发者把更多上下文留在模型工作流里。
昇腾不再只是“能跑”
澎湃号“光锥智能”5月1日发布的文章《中国AI算力的突围,昇腾生态的“破”与“立”》提到,DeepSeek V4 预览版在4月24日发布并开源后,华为几乎同步宣布昇腾 950、A3 系列超节点完成 DeepSeek V4 全版本“发布即适配”与全链路优化。
该文还提到,DeepSeek V4 技术报告首次将昇腾 NPU 与英伟达 GPU 并列写入硬件验证清单,细粒度 EP 专家并行方案在两类平台均完成验证。对昇腾来说,这比“兼容某个模型”更进一步:它进入了模型发布和验证链条。
另有其他媒体产业链分析称,DeepSeek V4 在昇腾 950 超节点上的 8K 输入场景下实现约 20ms TPOT,单卡 Decode 吞吐约 4700 TPS。该数据来自市场分析文章,不是 DeepSeek 官方定价页内容,但它解释了为什么外界会把昇腾放进 V4 Pro 成本讨论里。
CANN 的变化降低迁移门槛
澎湃号文章把昇腾生态的变化放在 CANN 上讲得很重。CANN 是华为面向 NPU 的异构计算架构,作用类似于英伟达 GPU 生态中的 CUDA。文章称,昇腾没有选择做“CUDA 复制品”,而是重构 CANN,把底层虚拟指令集、编译器和运行时能力掌握在自己手里。
更关键的是开放方式。文章援引华为昇腾专家的说法称,CANN 正在把原来“像麻花团一样团在一起”的能力拆开,让开发者能看见、能调用,并逐步开源。昇腾还与 Triton、PyTorch、vLLM 等 90 多个主流 AI 开源社区对接,并成为国内首个 Triton 原生认证后端。
这些变化和 V4 Pro 降价没有直接因果证明,但它们指向同一个问题:国产推理生态正在从“硬件可用”走向“开发者可迁移”。大模型服务商关心的不只是芯片峰值算力,还包括算子、框架、调度、工具链和社区支持。迁移成本降下来,国产算力才可能进入真实业务成本表。
价格下降背后是多条曲线相交
DeepSeek 官方页面没有说明 V4 Pro 降价原因,也没有提到昇腾、Ascend、950 或超节点。因此,不能把这次降价直接归因于昇腾。
但把公开信息放在同一时间线上看,几个变化确实在同时发生:DeepSeek V4 Pro 把长上下文推理成本大幅压低;DeepSeek 官方 API 把 Pro 版价格正式降至原价四分之一;华为昇腾 950 和 A3 系列超节点宣布完成 DeepSeek V4 全版本适配;CANN 生态继续开源和兼容主流框架。
这些变化共同指向一个结果:大模型 API 的成本结构正在松动。过去,模型服务价格主要受限于海外高端 GPU、CUDA 生态和长上下文推理成本。现在,模型架构优化和国产推理生态成熟开始同时进入这张成本表。
训练国产化仍需证据
这轮讨论里,最容易被写过头的是“国产 GPU 训练”。目前公开材料更明确支持的是推理适配和部署能力,而不是 DeepSeek V4 Pro 已经完全基于国产 GPU 完成训练。
训练和推理是两件事。训练需要长周期、大规模集群稳定性、通信效率和容错能力;推理更接近上线后的服务成本、吞吐和并发。昇腾完成 DeepSeek V4 适配,可以说明国产 NPU 在推理和生态验证上向前走了一步,但不能自动推出训练链路已经完全国产化。
这也是判断这次降价时需要保留的边界:V4 Pro 的长期低价,有明确证据支持的是模型效率提升和 DeepSeek 官方定价策略;昇腾生态提供的是国产推理供给改善的产业背景。
企业会重新计算 Agent 成本
OpenRouter 等第三方平台显示,DeepSeek direct 的 V4 Pro 价格明显低于多数第三方供应商。官方直连价格为输入 0.435 美元、输出 0.87 美元、缓存读取 0.003625 美元;部分第三方供应商价格则更接近原价区间。
这会迫使企业重新计算一些原本被搁置的 AI 应用。长上下文代码分析、企业知识库问答、多轮 Agent 执行、批量文档处理,以前常常不是技术上不可行,而是调用成本不稳定。V4 Pro 的新价格给这些场景留出了更大空间。
低价也有边界。DeepSeek 官方页面显示,V4 Pro 的并发限制为 500,V4 Flash 为 2500。对低延迟、高并发任务来说,Flash 仍可能更合适。V4 Pro 更适合强能力、长上下文和低单价同时重要的场景。
国产算力进入价格叙事
DeepSeek V4 Pro 的调价,把前沿模型 API 的价格锚往下拉了一段。昇腾生态的同步推进,则让国产推理算力第一次如此自然地进入成本讨论。
这并不意味着昇腾已经被官方确认为 V4 Pro 降价的直接原因。更准确的判断是:DeepSeek 先用模型架构降低了长上下文推理成本,再用官方定价把成本优势释放给开发者;与此同时,昇腾 950、A3 超节点和 CANN 生态的进展,让国产推理供给成为这条价格曲线能否持续的重要变量。
大模型价格战过去常被看成补贴战。V4 Pro 这次更像是另一种信号:当模型效率提升、推理生态成熟和国产算力供给同时推进,API 价格不再只是营销动作,而是产业成本变化的外显。