,AI 模型评测机构 Artificial Analysis 在 X 发布 Qwen3.7 Max 测评结果。数据显示,阿里新的 Qwen3.7 Max 在 Artificial Analysis Intelligence Index 上拿到 56.6 分,比 4 月发布的 Qwen3.6 Max Preview 高 4.8 分。
Artificial Analysis 的判断很直接:阿里仍落后于 OpenAI、Anthropic 和 Google 的模型,但 Qwen3.7 Max 是阿里迄今最接近前沿模型的一次。
Max 继续闭源,其他 Qwen 线保持开源
Qwen3.7 Max 是阿里 Qwen 系列最新的专有旗舰模型。Artificial Analysis 提到,从 2025 年 1 月的 Qwen2.5 Max 开始,阿里一直把 Max 和 Plus 模型做成闭源权重,而 Qwen 系列其他模型继续开放权重。
在开源 Qwen 模型中,目前 Intelligence Index 得分最高的是 2026 年 4 月发布的 Qwen3.6 27B Reasoning,得分为 45.8。开源 MoE Qwen 中领先的是 2026 年 2 月发布的 Qwen3.5 397B A17B Reasoning,得分为 45.0。
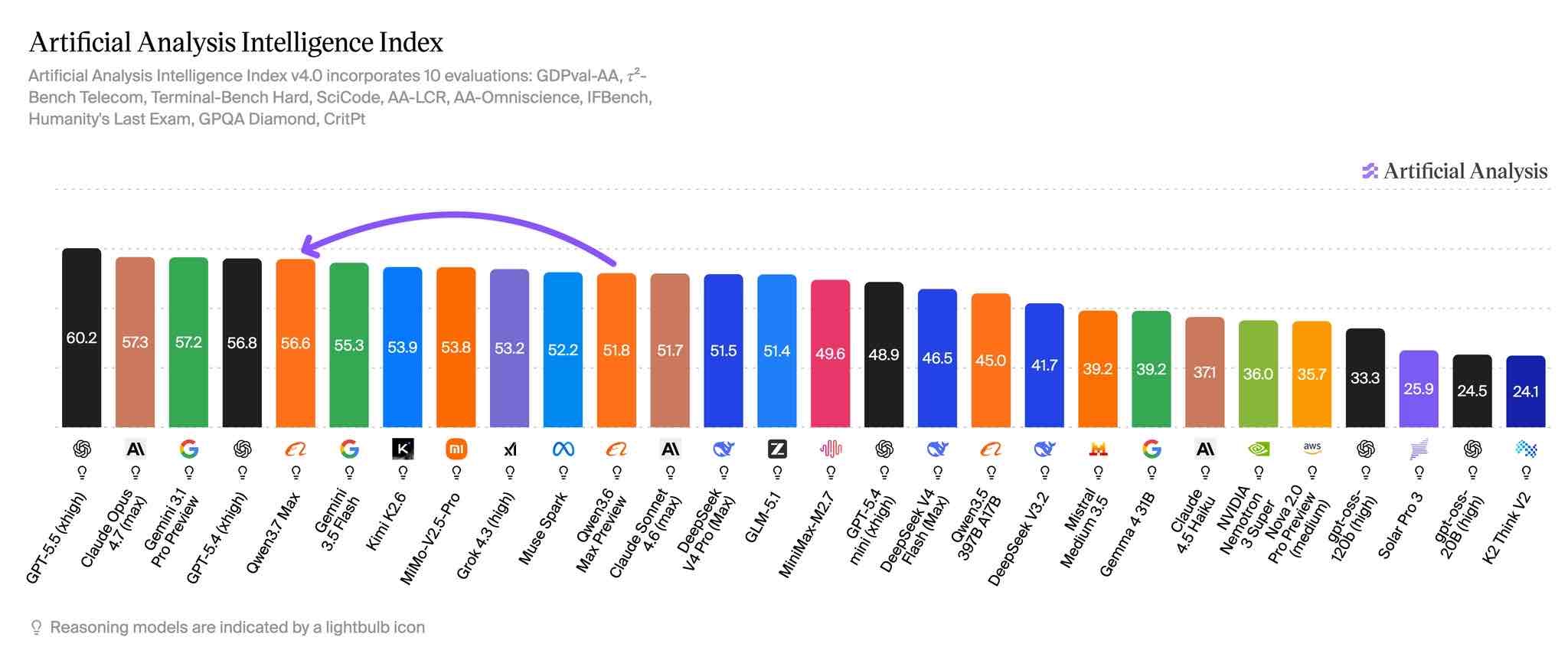
提升主要来自科学推理、智能体能力和代码
与 Qwen3.6 Max Preview 相比,Qwen3.7 Max 的提升集中在几个测试项上。CritPt 从 3.7% 升至 13.4%,提高 9.7 个百分点;HLE 从 28.9% 升至 38.1%,提高 9.2 个百分点;TerminalBench Hard 从 43.9% 升至 50.8%,提高 6.9 个百分点;GDPval-AA 从 1504 Elo 升至 1546 Elo。
换句话说,这次进步更像是集中补强,而不是所有指标一起上涨。Artificial Analysis 也说,Intelligence Index 中其他基准测试与 Qwen3.6 Max Preview 相比基本持平。
少答错了,但也少回答了
这次得分上涨里,有一个细节值得单独看。Artificial Analysis 称,Qwen3.7 Max 在 AA-Omniscience 上的准确率从 37.7% 降到 30.1%,下降 7.6 个百分点;但幻觉率从 44.2% 降到 22.9%,下降 21.3 个百分点。
这说明模型不是记住了更多事实,而是更愿意在不确定时不回答。由于 Intelligence Index 同时计算准确率和幻觉率,幻觉减少成了这次总分增加的主要来源之一。这对真实使用其实不坏。胡说八道少一点,总比自信编答案强。
上下文窗口升至 100 万 tokens
模型细节方面,Qwen3.7 Max 的上下文窗口从 Qwen3.6 Max Preview 的 256K tokens 提升到 100 万 tokens。Artificial Analysis 提到,该模型目前只支持文本输入和文本输出,不是多模态模型。
价格尚未公布。作为参考,Qwen3.6 Max Preview 在阿里云一方 API 上的价格是每 100 万输入 tokens 1.30 美元、每 100 万输出 tokens 7.80 美元。Qwen3.7 Max 为专有模型,闭源权重。
跑完整套评测用了 9670 万输出 tokens
Artificial Analysis 还披露了测试过程中的输出 token 用量。Qwen3.7 Max 跑完 Intelligence Index 使用了 9670 万输出 tokens,比 Qwen3.6 Max Preview 的 7390 万多约 31%。
在前沿模型里,这个用量处于中间位置。它高于 GPT-5.5 high 的 4450 万和 Gemini 3.1 Pro Preview 的 5730 万,低于 Claude Opus 4.7 Adaptive Reasoning Max Effort 的 1.12 亿、Kimi K2.6 的 1.66 亿,以及 DeepSeek V4 Pro Reasoning Max Effort 的 1.87 亿。
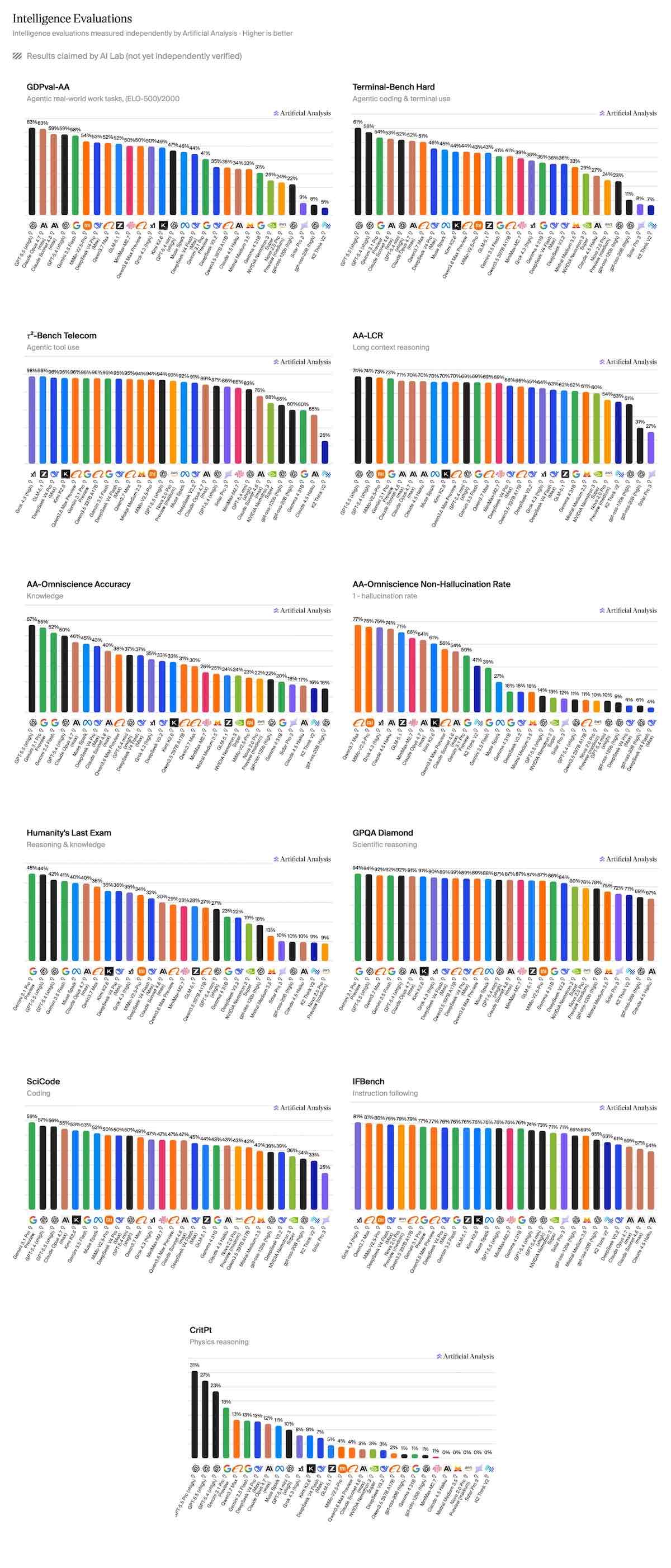
这组数据给 Qwen3.7 Max 的位置画得比较清楚:它还不是第一梯队最强模型,但差距变小了。对阿里来说,真正的问题可能不是这次涨了多少分,而是下一代 Max 能不能把这种接近变成稳定追平。