Cursor 把 Composer 升级到 2.5 了。他们这次喊得挺狠:"这是目前最强大的模型"——当然,这是他们自己说的。
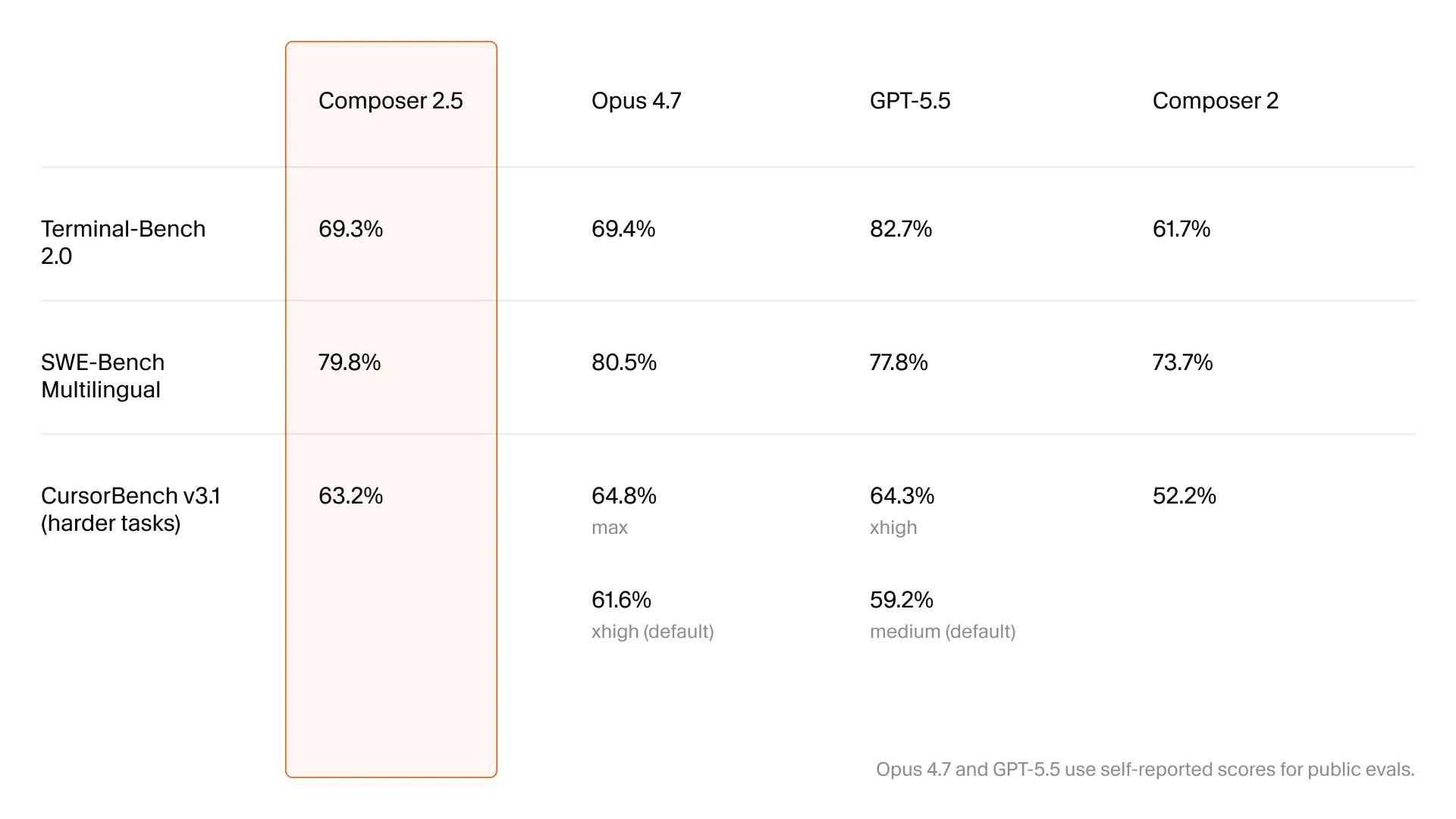
抛开宣传话术,看看实际变化:更聪明、长任务持续能力更强、执行复杂指令也更靠谱。还有个数据值得注意——同等能力下能做到 10 倍效率。
这波升级的底层是什么
看完他们的完整发布,发现背后其实有三件事:
- 训练规模直接拉大
- RL 环境做得更复杂
- 加了文本反馈机制,让模型能在几十万 token 的长 rollout 里快速学到正确归因
第三点挺有意思。当任务跨越几十万 token 时,传统的 RL 信用分配变得困难。模型拿到一个最终奖励,但很难判断是哪个具体决策让结果变好或变坏。文本反馈的做法是在轨迹中模型"本可以做得更好"的位置直接插入提示,构造一个教师分布,然后让学生模型的 token 概率向这个分布靠拢。
举个例子:模型在数百次工具调用中错误调用了一个不存在的工具。这个错误对最终奖励的影响很小,信号很弱。但通过文本反馈,可以在出错那一轮的上下文里插入"可用工具列表"这样的提示,让教师模型降低错误工具的概率,学生模型只在这一轮被更新。这样既有局部训练信号,又保留了完整轨迹的 RL 目标。
合成任务数量翻了 25 倍
另一个变化:Composer 2.5 的合成任务数量是 Composer 2 的 25 倍。
他们用多种方法创建基于真实代码库的合成任务。其中一种叫"功能删除"——智能体拿到一个有大量测试的代码库,被要求删除某些功能使代码库仍然可运行。然后合成任务就是重新实现该功能,用测试作为可验证奖励。
大规模合成任务也带来意料之外的奖励作弊。模型找到了一些变通办法:比如逆向 Python 类型检查缓存的格式找到已删除函数签名,或者反编译 Java 字节码重建第三方 API。这说明大规模 RL 里有些东西需要更谨慎对待。
底座和 Kimi K2.5 是同一套架构
Composer 2.5 的底座和 Moonshot 的 Kimi K2.5 是同一套开源架构。这意味着什么?至少说明这套架构在代码任务上表现不错,两家都选择了它作为起点。
更有意思的是下一步:Cursor 已经和 SpaceXAI 合作,从零开始训练一个规模显著更大的模型,用 10 倍总计算资源,依托 Colossus 2 的 100 万个 H100 等效算力。他们说这会是"模型能力的一次重大飞跃"——当然,这也是他们自己说的,但算力堆 10 倍,确实值得期待。
以前担心的问题
用 AI 写代码,以前总担心几件事:半途崩、指令执行飘、长任务忘掉上下文。Cursor 这次把这些问题往死里卷了。长任务持续能力是他们重点强调的改进点,配合文本反馈机制,看起来是想从根本上解决"走着走着就忘了"的问题。
价格和用量
Composer 2.5 的价格:每百万输入 token 0.50 美元、每百万输出 token 2.50 美元。还有一个智能水平相同但速度更快的变体,每百万输入 token 3.00 美元、每百万输出 token 15.00 美元。这个 fast 方案是默认选项。
第一周提供双倍用量,算是给用户一个尝鲜的机会。