市面上关于 AI Agent 的文章很多,吹得天花乱坠的也不少。我想知道的其实很简单——把那些框架、库、封装层都剥掉之后,一个 Agent 的核心到底是什么?
于是我自己写了一个大概 300 行的简化版 ReAct Agent。代码散落了不少地方,但终于坐下来把它们拼到了一起。
先画伪代码,再看论文,最后跟 Agent 聊天
我没有一上来就写代码。先画了个伪代码框架,读了几篇塑造了当前生产级 Agent 设计的论文,然后去跟主流 Agent 对话,填补了我理解上的空白。最后得到的循环是这样的:
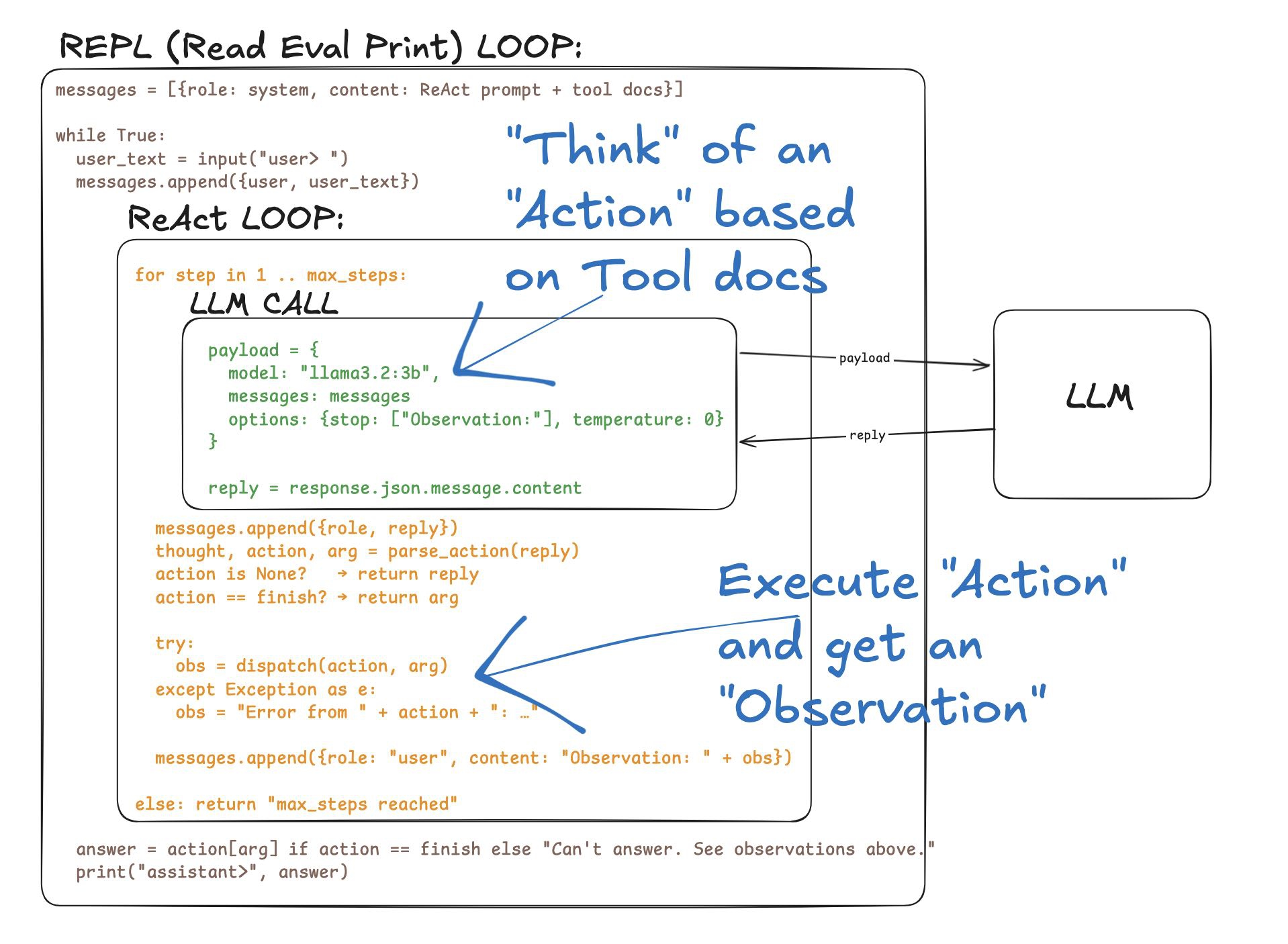
逻辑很简单:给定一个目标,Agent 在循环中反复「思考 → 行动 → 观察」,直到完成任务或达到最大步数。每一步,模型接收完整的对话历史,决定下一步做什么,然后执行对应的 Action,把结果加回历史,进入下一轮。
写完之后跑了跑,用的是本地的小模型而不是前沿大模型。结果嘛——有时候会答错。而且一个错误的步骤就能污染整条链路,后面全歪了。
但核心结构就是这么几行。
真正的重点:Action 可以是一切
这个简单循环让我最在意的一点是:Action 可以是任何函数调用。你把什么函数暴露给它,它就能做什么。
这意味着当你给 Agent 挂了 shell.exec,你同时也给了它 rm -rf 的能力。模型可以随意删除你的文件,没有任何限制。
之前那些生产事故标题大家都看过——Agent 把密钥写进了 git commit,把 source.zip 推到了 npm 仓库,在没有权限的 shell 里乱跑。这些事之所以发生,不是因为 Agent 有恶意,而是因为它的能力边界就是你暴露给它的那些函数。
这就像给一个不懂后果的小孩一串钥匙——钥匙能开保险箱,也能开垃圾房的门,你给的是什么,它就用的是什么。
上下文窗口才是烧钱的地方
ReAct 循环还暴露了另一个显而易见的事实:上下文窗口很贵。
因为每一步都要把全部历史重新发给模型。每一步。如果循环跑了 10 轮,你的 prompt 就会被发送 10 次。保持上下文小,否则每次迭代都在烧钱。
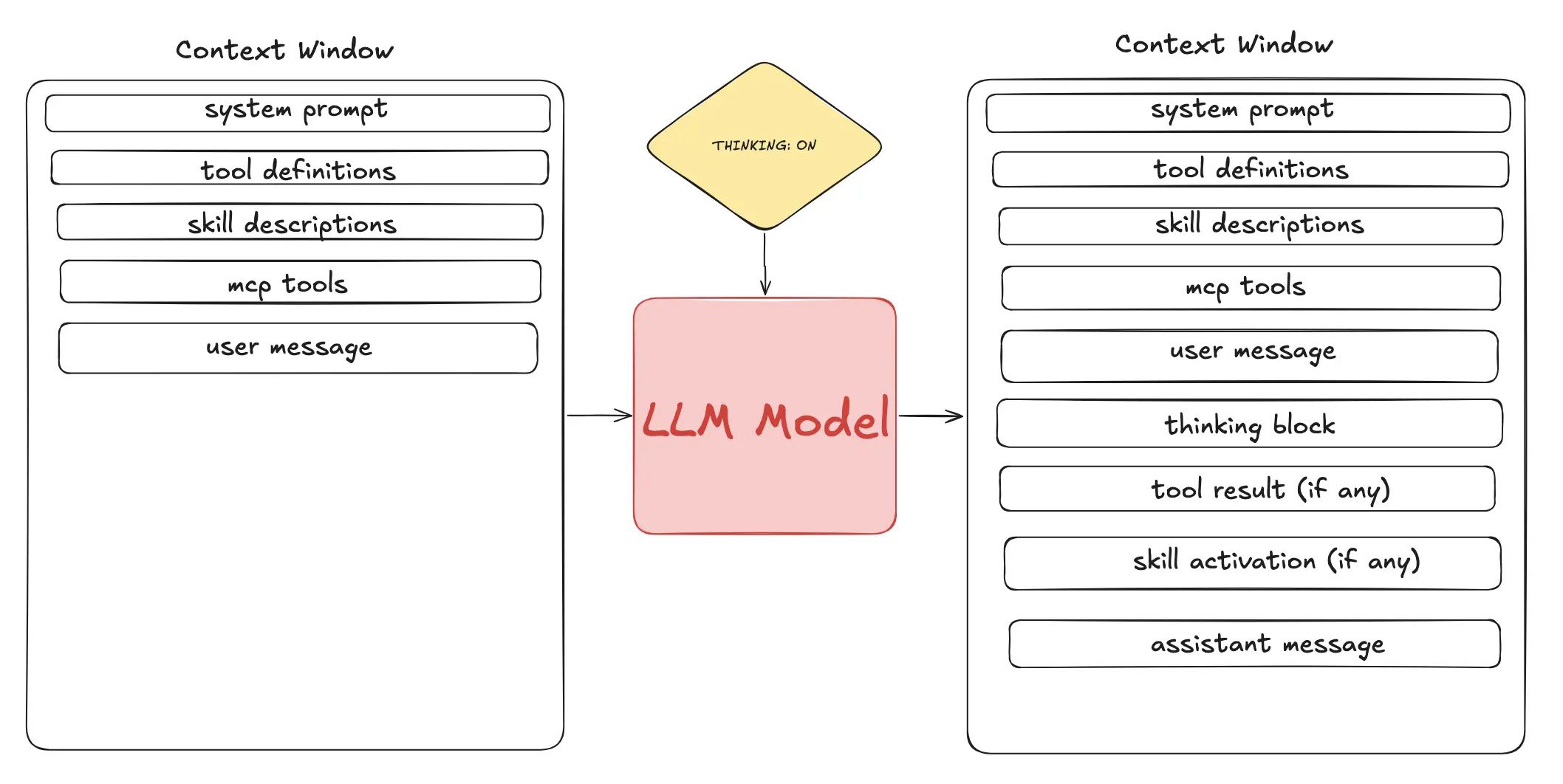
市面上确实有各种变通方案——prompt 缓存、压缩、摘要。但说实话,帮用户省 token 对模型提供商没好处。这就是他们的盈利模式。
软件工程师应该做什么
与其依赖通用的"助手",不如认真对待上下文管理,为自己的领域构建定制化的 Agent。
在定制 Agent 里,Action 应该是你真正需要的东西:
- 内部 API 调用
- 告警生成
- 数据库查询
- 网络搜索
- 内部流程执行
而不是把通用 shell 直接暴露给模型。
写了这个循环之后
一旦你自己写过这个循环,所有「AI 助手」都不再是黑盒了。你会开始问对的问题:
- 我的上下文里到底装了什么?
- 我的工具能碰到什么?
- 模型出错的时候会发生什么?
- Prompt 的质量有多关键?(提示:非常关键。)
这些才是 Agent 开发中真正重要的问题。框架会换,模型会升级,但核心的循环逻辑——观察、思考、行动——不会变。理解了这一点,再去看那些花里胡哨的 Agent 框架,你就知道它们只是在上面加了多少层包装而已。
参考原文:What's actually inside an AI agent: a 300~ LoC ReAct loop