Design Arena刚发布了Agentic Slides排行榜。在讲结果之前,先说说这个榜单是什么来头。
Design Arena是什么
Design Arena是Arcada Labs做的一个AI设计能力评测平台,也是目前全球最大的AI设计众包基准测试。它和Arena.ai(综合评测)、BridgeBench.ai(代码评测)并列,是目前少数几个靠真实用户投票、而不是靠刷题来排名的AI榜单。
平台有380万+用户,覆盖190多个国家。评测方式很直接:给两个模型同样的设计prompt,把结果匿名摆在用户面前,用户投票选哪个更好。排名算法用的是Bradley-Terry模型,和国际象棋的Elo评分类似——每投一票,模型的相对排名就更新一次。
覆盖的设计类别有十几个:网站设计、UI组件、移动应用、3D设计、游戏开发、数据可视化、Logo、SVG、ASCII艺术、视频,还有我们要说的Slides(幻灯片)。
Agentic Slides怎么评的
Slides Arena是Design Arena下的一个子榜单,专门评AI生成幻灯片的能力。370多万人在平台上做幻灯片,系统随机分配两个模型生成,用户选哪个更好。没有预设的评分标准,就是用户觉得哪个好用。
这种方式叫"soft-verifiable"——不像代码可以跑测试,幻灯片好不好用很主观。但样本量够大,370万用户的选择还是能说明问题的。
另外值得一提的是,这个榜单用的是修改版的开源agent harness,模型可以调用generate_image等工具。也就是说,评的不只是"写文字"能力,还包括"做设计"的综合能力。
前三名
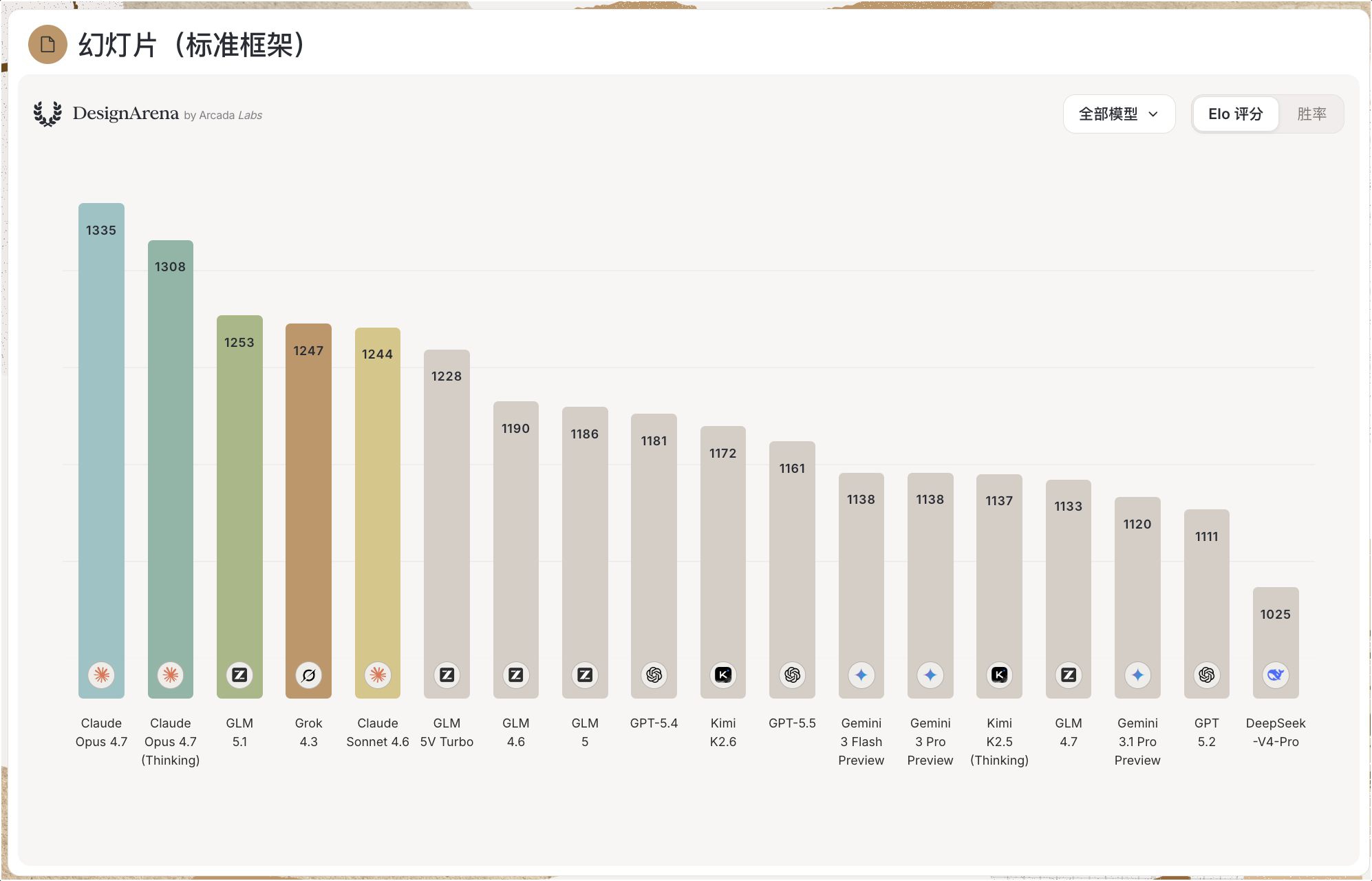
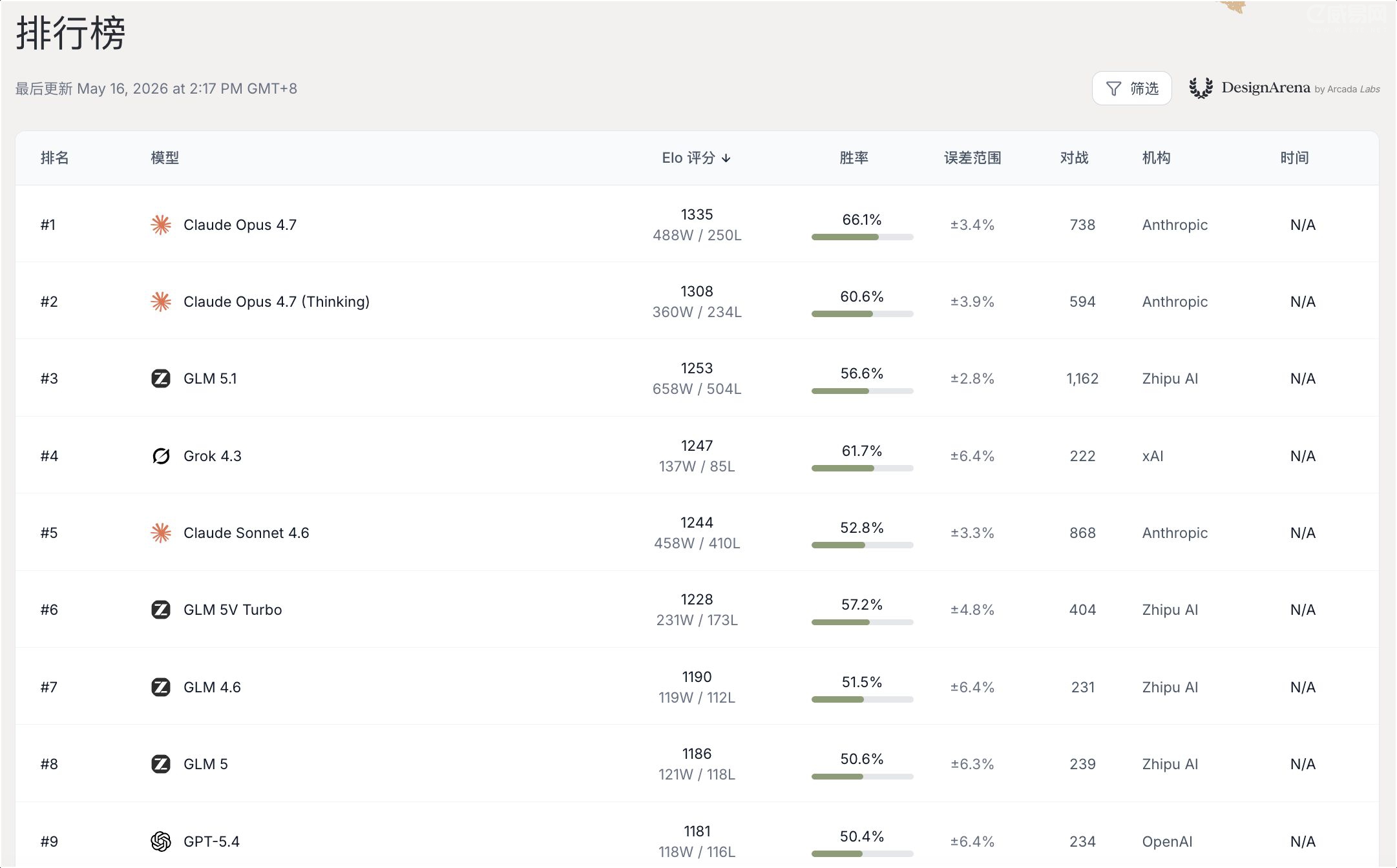
Claude Opus 4.7拿了第一,Elo 1335,胜率66.1%,738场对战。第二是Opus 4.7的Thinking版本,Elo 1308,胜率60.6%。第三是智谱AI的GLM 5.1,Elo 1253,胜率56.6%,打了1162场。
Anthropic包揽前二,智谱AI守住第三。这个格局和之前差不多,两家在soft-verifiable domains一直领先。
有意思的几个点
Grok 4.3排第四,Elo 1247,胜率61.7%。但只打了222场,样本量偏少,这个排名可能不太稳。
Claude Sonnet 4.6排第五,Elo 1244,胜率52.8%。比Opus低了91个Elo,但胜率刚过半。说明Sonnet赢得多的局赢得不太干脆,输的局输得也不算惨。
OpenAI的GPT-5.4和GPT-5.5分别排第九和第十一,Elo都在1180左右,胜率刚好50%。不上不下,挺尴尬的位置。
Google的Gemini 3 Flash Preview和Pro Preview并列第十二,Elo 1138,胜率都在44%左右。和前面的差距有点大。
国产模型的表现
智谱AI这次挺亮眼。GLM 5.1排第三,GLM 5V Turbo排第六,GLM 4.6排第七,GLM 5排第八。前八名占了四席。
不过也有隐忧。GLM 5.1打了1162场,是所有模型里最多的,但胜率只有56.6%。相比之下,Opus 4.7只打了738场,胜率却有66.1%。场次多说明用户选得多,但胜率才是硬指标。
Moonshot AI的Kimi K2.6排第十,打了1098场,胜率44%。场次第二多,但胜率没过半。用户爱用,但用完觉得还是差点意思。
Thinking模式有用吗
Opus 4.7的Thinking版本比普通版低了27个Elo,胜率也从66.1%降到60.6%。这有点反直觉——按理说"思考"应该更聪明才对。
可能的解释:幻灯片生成不需要太深的推理,快速出结果更重要。Thinking模式花更多时间"思考",但用户等不及,或者结果反而过度复杂。
怎么看这个结果
说实话,我不太确定这种排行榜能说明多大问题。幻灯片好不好用,很大程度取决于具体场景。做商业汇报和做学术答辩,需求完全不一样。370万用户的选择是平均值,落到个人头上可能完全不同。
但有一点是确定的:Anthropic和智谱AI在这个赛道确实有优势。至于能不能保持,得看后续的模型更新。