18个月,100亿美元。世界模型到底在炒概念,还是在造下一个 LLM?
从一个场景开始
一个机器人从没见过鞋带。没有人教它怎么解。但它伸出手,抓住鞋带,拉了一下,松开了。成功了。
因为它在脑海里"练习"过。
它看过成千上万小时人类双手操作的画面,学会了拉、拧、推时物体会怎么动,然后在动手之前先在脑子里想象结果。这个"脑海里的练习场",就是世界模型。
不是用文字描述世界的语言模型,不是生成视频的画面生成器,而是对物理世界运行规律的建模。能预测接下来会发生什么,并根据预测采取行动。
"世界模型"这个词被用烂了
过去18个月,超过100亿美元砸进了"世界模型"这个赛道。Yann LeCun 离开 Meta 去建一个。Danijar Hafner(Dreamer 系列作者)离开 DeepMind 去商业化一个。NVIDIA 开源了一整套。OpenAI 关掉 Sora,声称转向"用于机器人的世界模拟",然后项目负责人三周后离职了。
但大部分被称为"世界模型"的东西,根本不算。视频生成器、RL 梦境机器、抽象表征学习器、动作预测基础模型——全被塞进了同一个标签。
要搞清楚什么是真正的世界模型,得从两条独立发展了几十年的研究路线说起。它们在 2024 到 2025 年间合并了。
路线A:学会做梦(RL世界模型,1990-2025)
"智能体应该在脑子里建一个世界的内部模型"这个想法,比深度学习早得多。1943年 Kenneth Craik 就提出人大脑里装着现实的"小尺度模型"来预测事件。1990年 Schmidhuber 把它形式化为神经网络:智能体应该学习环境的不同模型并用它做规划。
这个想法沉寂了将近三十年。
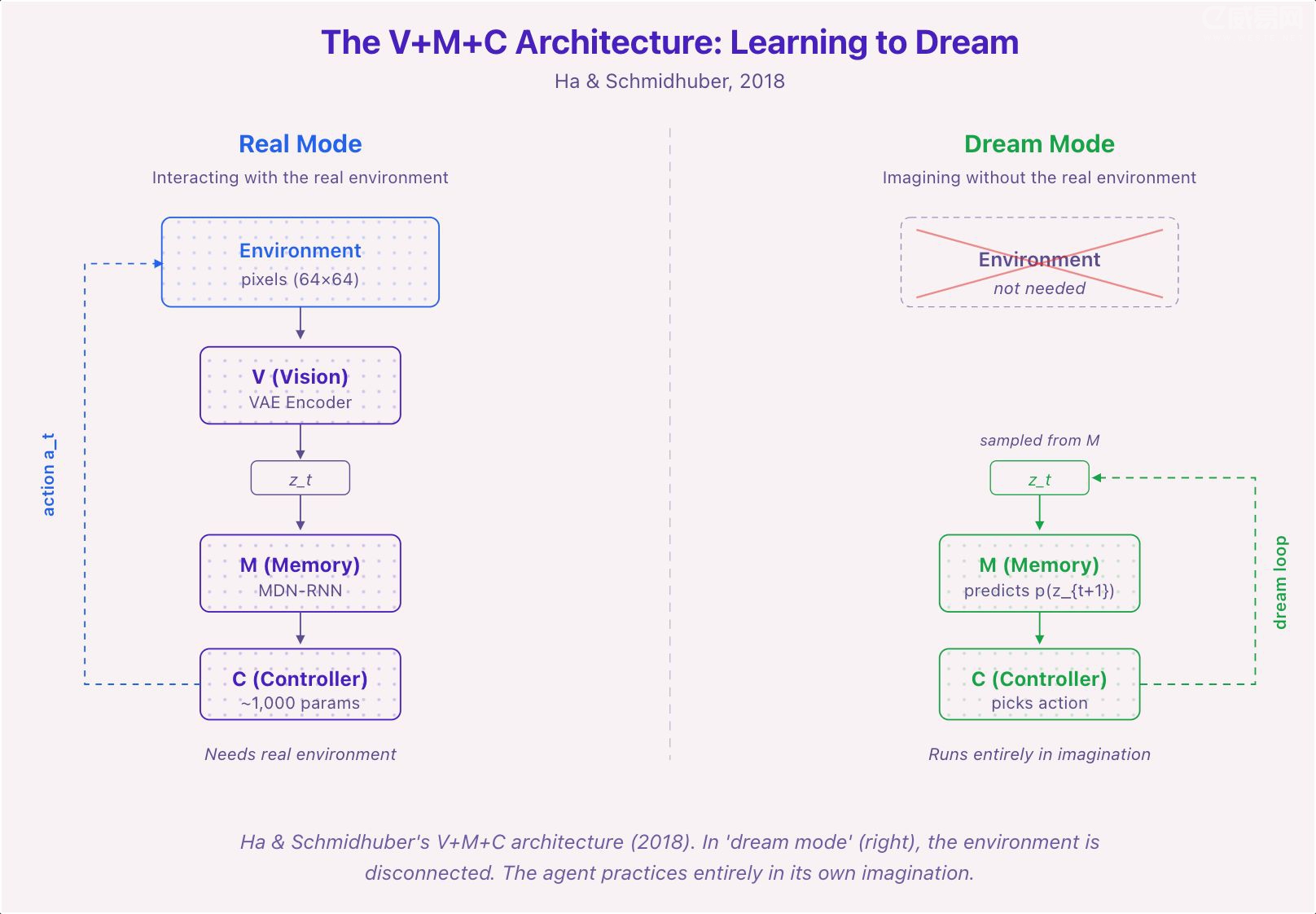
2018年,David Ha 和 Schmidhuber 用一篇名为"World Models"的论文把它复活了。架构是三个模块:VAE 压缩像素为潜在向量,MDN-RNN 预测动态,一个小小的控制器完全在想象的推演中训练策略。智能体在自己的梦里训练,然后部署到现实。能跑赛车游戏,能打 VizDoom。概念验证成功了。
Danijar Hafner 花了六年沿着同一条路走。他的 Dreamer 系列从简单连续控制(V1)到人类级 Atari(V2)再到用同一套超参数跑 150 多个基准测试(V3,2025年发表在 Nature 上),包括从零开始在 Minecraft 里挖钻石。Dreamer 4 在 2025 年底把循环骨干换成了 Transformer,快了 25 倍。
DayDreamer(2022)把它放到了真机器人上:一个四足机器人在一小时内从零学会走路。
这条路线做对了一件事:学动态,想象未来,在想象中训练策略而不是在现实中烧钱。这就是今天所有视频世界模型继承的核心思想。
但它做不到一件事:跨环境泛化。Dreamer 能在一个 Atari 游戏上达到人类水平,但学下一个游戏得从头训练。模型太小(百万级参数),梦境是人类看不懂的抽象向量,而且需要数千集特定任务的训练。
想法对了。规模不对。
路线B:学会观看(2016-2025)
另一条平行发展的路线是从视频中学。经历了三个阶段:
第一阶段:视频预测用于规划(2016-2018)
训练一个模型预测执行某个动作后摄像头会看到什么,然后选那个预测未来最接近目标的动作。能完成简单的推动任务,但预测几帧就糊了。太短太模糊,做不了复杂操作。
第二阶段:从人类视频学表征(2020-2022)
思路变了:不直接预测视频,而是用人类视频学视觉表征,然后迁移到机器人任务。R3M(Nair 等,2022)是突破:用 Ego4D 上数千小时人类第一人称做饭、打扫、操作物体的视频预训练编码器。Franka 机械臂用 R3M 特征仅凭 20 次演示就学会了操作任务,所需数据量大幅减少。
OpenAI 的 VPT(2022)展示了互联网规模视频预训练对学行为有效:用 7 万小时 Minecraft YouTube 游戏视频预训练的模型,少量演示就能微调成有能力的智能体。这是第一个证明海量无标注视频可以启动复杂序列任务行为的系统。
第三阶段:视频生成规模化(2022-2024)
扩散模型应用在视频上带来了质的飞跃。Sora(2024年2月)是转折点——生成的画面似乎服从物理规律:物体下落、光线散射、镜头跟踪令人信服。但 Sora 不是交互式的。它用的是双向注意力:所有帧同时看到所有其他帧。你无法在中间注入动作。它是一部电影,不是一个游戏。
两条路线的汇合(2024-2025)
RL 那边有动作条件化但不能泛化。视频那边有规模和真实感但没有交互性。2024 到 2026 年间的一系列工作把两者连起来了。
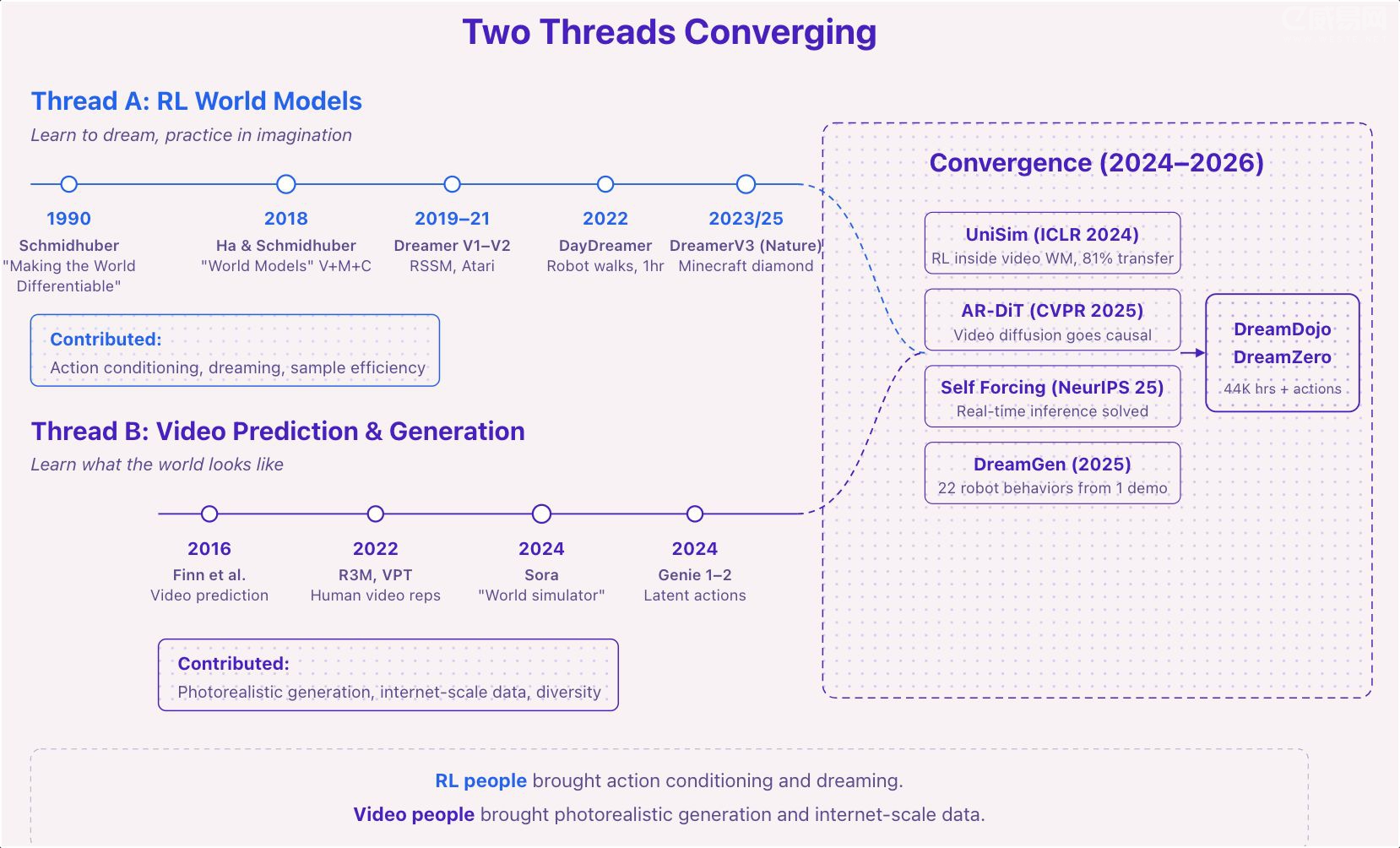
Genie(DeepMind)引入了潜在动作模型:从未标注视频中学习交互式环境。模型看两帧连续画面,把"变化了什么"压缩成一个小向量,不需要任何人标注动作就能发现动作空间。Genie 1 是 160x90 分辨率、1 FPS 的概念验证。Genie 2 做到了 720p 逼真画面、10-60 秒一致性。Genie 3 达到 24 FPS、720p、持续数分钟一致性。
两个关键技术突破扫清了最后的障碍。AR-DiT / CausVid(CVPR 2025)让视频扩散模型变成自回归和因果的——不再一次性生成所有帧,而是逐帧生成,基于过去的帧和当前动作。Self Forcing(NeurIPS 2025)解决了速度问题,把 35 步去噪蒸馏到 4 步,首次实现通用视频模型的实时交互生成。
DreamGen(NVIDIA,2025年5月)展示了视频世界模型如何让机器人用极少的真实数据实现泛化。方法是:用少量真实机器人画面微调视频生成模型,然后用语言指令提示它生成机器人从未做过的任务的合成视频。一个逆动力学模型从这些合成视频中提取运动指令,无需远程操作就能产生训练数据。一个人形机器人在陌生环境中完成了 22 种新行为,只靠一次抓取演示。
高潮是 DreamDojo 和 DreamZero(NVIDIA,2026年2月)。DreamDojo 是一个视频基础模型,在 44,711 小时人类第一人称视频上预训练,通过学习到的潜在动作空间进行动作条件化,用 Self Forcing 蒸馏到实时,能以 r=0.995 的相关系数评估机器人策略。DreamZero 更进一步,在一次前向传播中同时预测未来视频和机器人电机动作。
做 RL 的人带来了动作条件和"做梦"的概念。做视频的人带来了逼真的生成和互联网规模的数据。结果在架构上继承自视频生成,在哲学上继承自 RL 世界模型。
什么才是真正的世界模型?五条标准
不是所有视频模型都算世界模型。Xun Huang(几个系统使用的自回归扩散架构的共同作者)提出了五条区分标准:
| 属性 | 说明 | 性质 |
|---|---|---|
| 因果性 | 时间只能向前流。双向视频生成违反这条 | 硬性约束 |
| 交互性 | 实时响应动作。没有这个就是电影不是模拟 | 硬性约束 |
| 持续性 | 长时间保持连贯。当前模型维持数秒,Genie 3 到数分钟 | 连续谱 |
| 实时性 | 足够快以用于应用。当前最优:10-30 FPS | 连续谱 |
| 物理准确性 | 尊重真实世界物理规律 | 最难、最有争议 |
因果性和交互性是二元的。没有它们,就不算世界模型。剩下三条是连续谱——好坏之分,而不是有无之别。
世界模型到底能干什么?
从最成熟到最前瞻,五个应用场景:
自动驾驶模拟(最成熟)。Wayve(GAIA 世界模型,12 亿美元 D 轮)和 Waymo 都在用世界模型生成驾驶场景做测试。标准是能合成多样、真实的驾驶场景来压力测试自动驾驶策略。这个已经在生产中。
娱乐和游戏。Decart 的 Oasis 是一个完全由世界模型生成的可玩 Minecraft 式游戏,20 FPS,已经可以试玩。Genie 3 生成 24 FPS、720p 的可探索环境。GameNGen 在神经网络里跑 DOOM,20 FPS。xAI 宣布 2026 年底推出世界模型游戏(还没有 demo)。物理要求没那么高——玩家能接受一定不真实,只要体验好玩。但服务成本惊人:Genie 3 运行一小时大约 100 美元。
策略评估(机器人领域最清晰的近期价值)。DreamDojo 的预测和真实世界策略成功率之间的皮尔逊相关系数达到 r=0.995。这意味着你可以在世界模型里给 20 个候选策略排名,而不必做 20 次昂贵的真实实验,排名结果和现实几乎一致。世界模型变成了机器人行为的单元测试环境。
合成训练数据生成。DreamGen 让一个人形机器人用一次演示就能完成 22 种新行为。但研究者自己也承认提升是有限的——有一些增益,但不是领域期盼的那种跨越式飞跃。关键问题是:合成视频数据带来的信号,能不能超过更多远程操作数据或更好的数据增强?
直接机器人控制(最大胆、最未被证实的主张)。DreamZero 在一次前向传播中同时预测未来视频和电机动作,在自己的评估中报告比 VLA 基线好 2 倍泛化。但这是一篇论文,来自建造它自己的团队,没有独立复现。
机器人AI比看起来更早
诚实的说法不是"VLA 行,世界模型不行",而是机器人 AI 整体比 100 亿美元融资暗示的要早期得多。
导航和受限仓库分拣已经可靠。在受控实验室里做烹饪演示能行(ALOHA/Sunday 用 50 次演示在炒虾上达到 90%),但每道新菜都需要新演示。通用家务操作、家具组装、接触丰富的灵巧操作——无论哪种方法都没解决。
VLA 也没有停下脚步。Physical Intelligence 的 Pi-0.7(2026年4月)展示了组合泛化能力,能从不同任务中组合技能来解决新问题。它操作从未见过的空气炸锅时,会混合相关训练经验的片段。值得注意的是,Pi-0.7 本身是一个混合体:它依赖轻量级世界模型(基于 BAGEL 图像生成骨干)产生的子目标图像来规划多阶段任务。当今领先的 VLA 本身就集成了世界模型组件。
两种方法不是在竞争——它们在融合。
100亿美元的赌注
资金分布在四个层面:
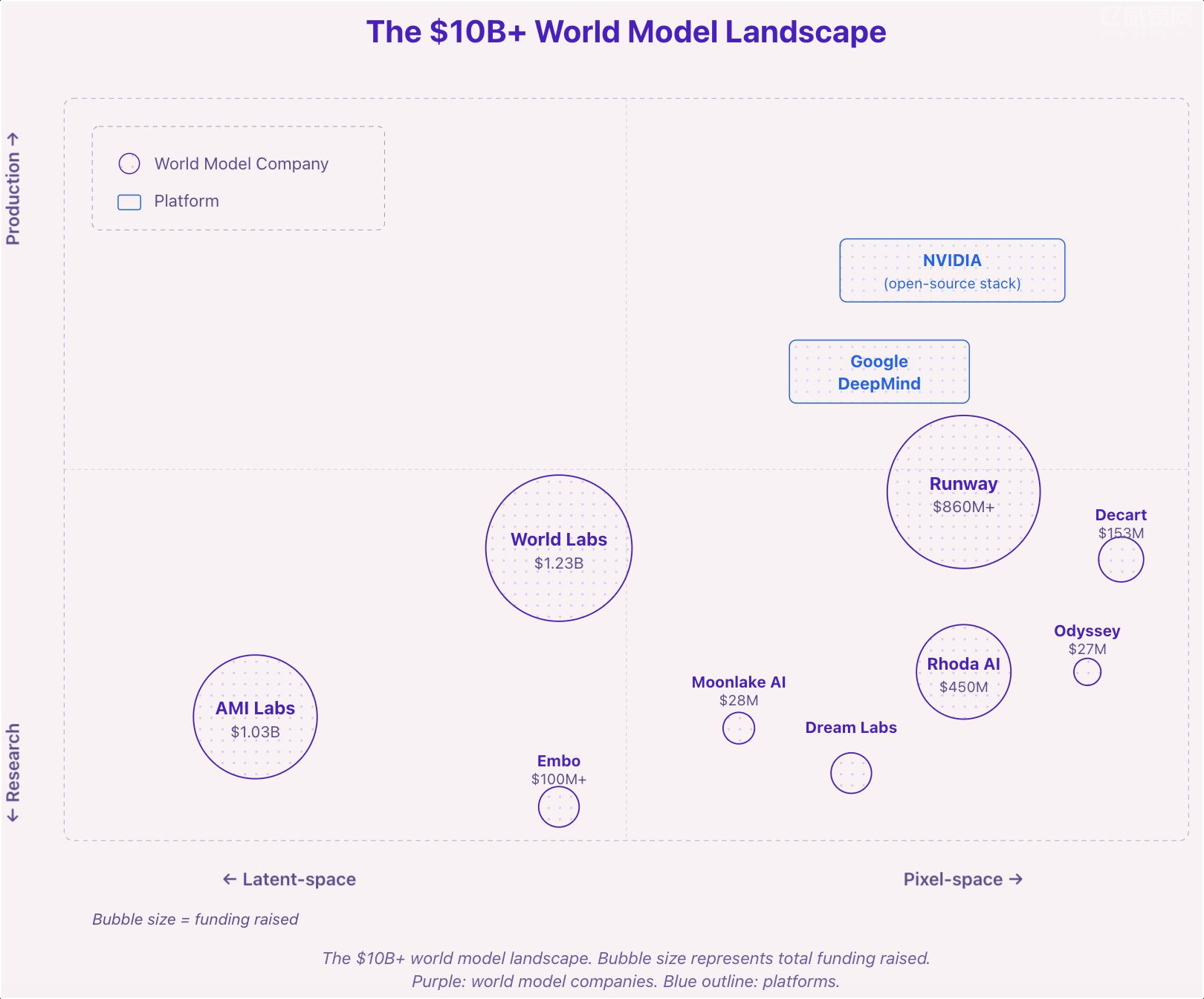
纯世界模型公司。AMI Labs(10.3 亿美元,欧洲最大种子轮)、World Labs(12.3 亿)、Runway(8.6 亿+)、Rhoda(4.5 亿)、Decart(1.53 亿)、Embo(1 亿+)。
机器人基础模型公司。Skild(18.3 亿)、Physical Intelligence(11 亿+)、Figure(20 亿+)、Mind Robotics(6.15 亿)。
平台层。NVIDIA、Google DeepMind 建设和开源基础设施。
大科技转型。OpenAI 的 Sora 后机器人计划、Tesla、xAI。
一个值得注意的模式:使用世界模型的公司筹集的资金超过了建造它们的公司。要么是世界模型层相对于其重要性资金不足,要么是最大的机器人公司会在内部构建这个能力。1X Technologies 已经这样做了。
NVIDIA:800磅的大猩猩
这个领域最重要的战略发展不是一家初创公司,而是 NVIDIA 构建了完整的物理 AI 栈并且开源了。
从 Cosmos Predict 2.5(视频基础模型,140 亿参数,2 亿视频片段)到 DreamDojo(动作条件化世界模型,4.4 万小时人类视频,r=0.995 策略评估)到 DreamZero(联合视频+动作预测,零样本迁移到新任务)到 EgoScale(缩放定律:人类视频时长与机器人性能之间 R²=0.9983)到 GR00T N2(产品化机器人大脑,2026 年底)。每一层都是 Apache 2.0 开源。
策略就是物理 AI 领域的 CUDA:免费给软件,卖硬件。DreamZero 跑在 7Hz,但只在 Blackwell GB200 上。H100 上跑不了实时。如果每个机器人公司都基于这个栈构建,它们都需要 Blackwell。
对于做纯世界模型的初创公司来说,这是生存级别的问题。DreamDojo 是免费的,训练了 4 万小时的视频。"我们做了一个世界模型"不再是护城河。差异化必须来自 NVIDIA 没有的领域特定数据、更快的推理,或者垂直整合成一个不只是模型的产品。
JEPA:反向押注
不是所有人都在做视频世界模型。Yann LeCun 和 Saining Xie 通过 AMI Labs(10.3 亿美元)在做反向押注。论点是:预测像素从根本上就是浪费的——大部分像素级细节和理解动态无关。
JEPA(联合嵌入预测架构)把观察编码成抽象表征,直接预测未来的表征,从不生成视频。V-JEPA 2 在 Meta 开发时,在超过一百万小时的互联网视频上预训练,然后仅在 62 小时的机器人数据上微调。它在零样本抓取和放置任务上达到 80% 成功率,没有生成一帧视频。
AMI Labs 现在有十亿美元来测试抽象预测是否能打败像素预测。反方意见是:像素级预测可能捕捉到抽象表征遗漏的物理细节,而且你可以看到视频模型认为会发生什么。JEPA 的预测是人类看不懂的抽象向量。
机会在哪
NVIDIA 的开源栈抛出一个现实问题:什么是可防御的?几个不同的机会类型:
前沿横向世界模型。最大胆的赌注:做一个比 NVIDIA 更好的通用世界模型。AMI Labs 用 JEPA 走这条路,Embo 有不同的架构哲学,Dream Labs 建立在 DreamGen 和 DreamDojo 的工作之上。Cosmos 和 DreamDojo 是新类别的 1.0 版本。架构跨越的空间是有的。
垂直特定世界模型。NVIDIA 的栈是通用的。专门为手术机器人、仓库操作或食品制备建世界模型的公司,用实际部署中的专有数据,可以切出一个通用模型无法匹配的护城河。类比:彭博终端 vs ChatGPT。两种都能做语言,但彭博的领域数据和工作流整合让它在金融领域不可替代。
卖铲子的层面。推理基础设施、评估平台、仿真到真实迁移工具、第一人称视频数据管道。这些不如"我们建了个世界模型"性感,但解决的是真实痛点:Genie 3 运行一小时约 100 美元,Odyssey 每个用户需要一台完整的 H200。风险是:NVIDIA 拥有硬件,而且推理优化是快速演进的研究,很快会被吸收到开源中。
"产品里的世界模型"。世界模型是垂直整合机器人产品的一个组件,不是产品本身。终端客户买的是结果——叠好的衣服、分拣好的包裹、冲好的浓缩咖啡——不是推理。模型是手段,机器人做有用的事才是产品。
写在最后
NVIDIA 的 GEAR Lab 负责人 Jim Fan 给正在发生的事情起了个名字:大并行。机器人学正在一步步复制 LLM 的剧本。世界模型是预训练阶段——学模拟下一个物理状态,就像 GPT 学预测下一个 token。动作微调把那个模拟收缩到对真实机器人有意义的那一部分。强化学习跑完最后一公里。同一个三步配方,让 LLM 在六年内从 GPT-3 走到 o1。
如果这个并行成立,我们已经拥有的系统——一小时内学会走路的机器人、可以穿越其中的视频模型、与真实结果 r=0.995 相关的预测——就是物理 AI 的 GPT-2。三年前这些全都不存在。
两条独立发展了几十年的研究路线合并成了真正新的东西:能想象物理未来、实时响应动作、从人类视频迁移知识到机器人的机器。
这个赌注能不能兑现,取决于"梦到世界"这件事对于最难的操作任务是否重要——那些光看足够多例子不够、你必须预测推拉扯会发生什么的任务。
我们认为会。时间线没有 100 亿美元暗示的那么确定。
原文来自 MoE Capital:The Model That Dreams the World