你是否想过,只需一段 3 秒钟的音频剪辑,就能完美复刻任何人的声音?近日,基于 Qwen2-Audio (Qwen3-TTS) 原生实现的桌面工具 —— VoiceBox 正式开源。它不仅打破了声音克隆的门槛,更重要的是,它实现了 100% 本地运行,彻底解决了隐私泄露的后顾之忧。
1. 什么是 VoiceBox?
VoiceBox 是由开发者 Jamie Pine 推出的一款开源桌面应用。它是阿里巴巴 Qwen 系列语音模型(Qwen3-TTS 核心)的首个原生桌面端实现。与那些需要上传云端、按量计费的商业服务不同,VoiceBox 旨在让每一个拥有普通电脑的用户都能掌控顶级的 AI 语音技术。
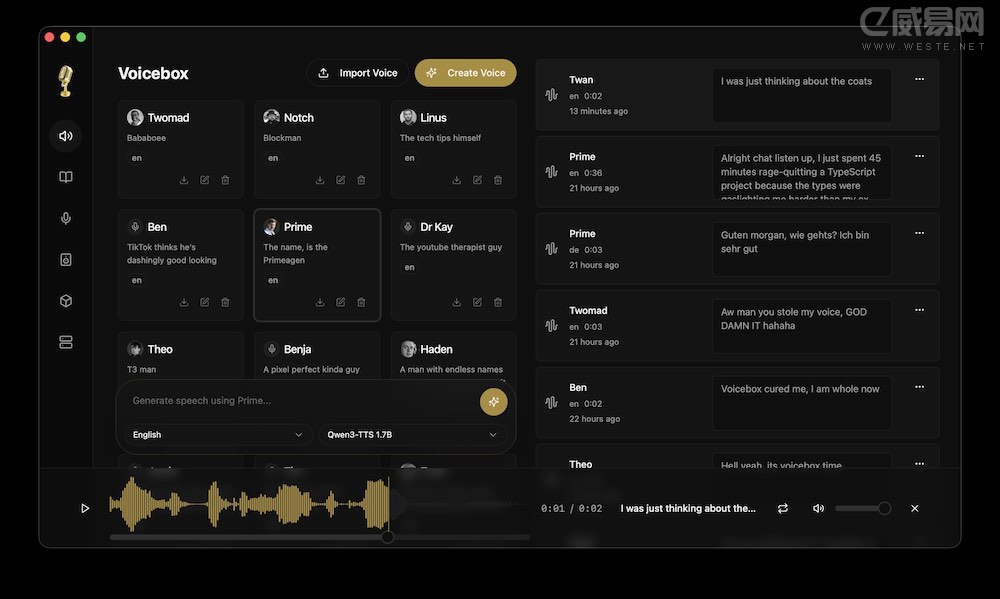
2. 核心震撼功能
- 瞬时克隆(Instant Cloning): 只需拖入一段 3 秒钟的参考音频,模型即可精准捕捉音色特征。
- Qwen3-TTS 原生驱动: 依托强大的 Qwen2-Audio 系列模型,它在处理复杂语境和长文本时表现极佳。
- 情绪与韵律掌控: 能够完美还原人类交谈中的细微情绪波动,不再是冷冰冰的机器音。
- 多语言切换: 原生支持多语言混合输入,无论是中文、英文还是其他主流语种,切换极其自然。
- 100% 隐私安全: 所有推理过程均在你的显卡或 CPU 上完成,数据无需出户。
3. 为什么它值得你部署?
在目前的 TTS 开源界,VoiceBox 的出现解决了一个巨大的痛点:易用性。
以往运行这类模型需要复杂的 Python 环境配置,而 VoiceBox 提供了极简的桌面端交互:
- 零配置上手: 适配了主流操作系统的桌面客户端,安装即用。
- 高性能推理: 针对家用显卡进行了优化,克隆与生成速度极快。
- 完全开源: 无论是模型还是前端代码都公开透明,遵循开源社区精神。
4. 应用场景想象
拥有了 VoiceBox,你可以轻松实现以下操作:
- 个性化有声书: 用自己或者家人的声音为孩子读故事。
- 视频博主福利: 只需录制几句样本,后续所有的旁白都可以通过打字生成,极大地缩短工作流。
- 多语言翻译: 保持原音色不变的情况下,生成地道的异国语言配音。
5. 获取与安装
如果你已经等不及想体验这款“声音克隆神器”,可以访问其 GitHub 仓库获取最新的 Beta 版本。目前该项目正处于快速迭代中,Star 数正在飙升。
- 项目地址:jamiepine/voicebox
- 底层模型:基于 Qwen2-Audio 系列
技术寄语: 技术的进步正在模糊虚构与现实的界限。VoiceBox 让我们看到了本地化 AI 的巨大潜力,但在使用的过程中,也请务必遵守道德底线,尊重他人的声音版权。