œκœσ“Μœ¬Θ§Ρψ «“ΜΟϊ άΫγΕΞΦΕΒΡ≥χ ΠΘ®¥σΡΘ–ΆΘ©Θ§±Μ«κΒΫ“ΜΗωΡΑ…ζΒΡ≥χΖΩΘ®Άβ≤Ω άΫγΘ©άοΉω≤ΥΓΘœ÷‘ΎΘ§Ρψ–η“Σ”ΟΒΫΗς÷÷≥χΨΏΚΆ ≥≤ΡΘ®ΙΛΨΏΚΆΖΰΈώΘ©ΓΘ
≥ΓΨΑ“ΜΘΚΟφΕ‘Τ’Ά®APIΒΡ≥χΖΩ’βΗω≥χΖΩάοΘ§Υυ”–ΒΡΕΪΈςΕΦΥχ‘ΎΧυΉ≈≤ΜΆ§±ξ«©ΒΡΙώΉ”άοΓΘ±ξ«©…œ–¥ΒΡ≤Μ «÷–ΈΡΘ§Εχ «Η¥‘”ΒΡΟή¬κΘ®APIΈΡΒΒΘ©ΓΘΟΩΗωΙώΉ”ΕΦ–η“Σ≤ΜΆ§ΒΡ‘Ω≥ΉΘ®»œ÷ΛΖΫ ΫΘ©Θ§”–ΒΡ–η“Σ÷ΗΈΤΘ§”–ΒΡ–η“ΣΥΔΩ®ΓΘΡψœκΡΟΗωΙχΘ§ΒΟœ»Ζ≠“κ±ξ«©ΓΔ’“ΒΫΕ‘”ΠΒΡ‘Ω≥ΉΘ§»ΜΚσ¥ρΩΣΙώΉ”ΓΘΙΊΦϋ «Θ§ΉωΆξ“ΜΒά≤ΥΚσΘ§Υυ”–ΙώΉ””÷ΜαΉ‘Ε·Υχ…œΘ§œ¬“ΜΒά≤ΥΡψΒΟ÷Ί–¬ά¥ΙΐΓΘ
≥ΓΨΑΕΰΘΚΟφΕ‘MCPΒΡ≥χΖΩ’βΗω≥χΖΩ «ΈΣΡψΝΩ…μΕ®÷ΤΒΡΓΘΡψ“ΜΫχΟ≈Θ§ΨΆ”–“ΜΗω÷«Ρή÷ζ ÷Θ®MCPΩΆΜßΕΥΘ©ΒίΗχΡψ“ΜΖί«εΒΞΘ§…œΟφ«εΈζΒΊ–¥Ή≈ΘΚ“≥ιΧκ1ΘΚ≥¥ΙχΘΜ≥ιΧκ2ΘΚΒςΈΕΝœΘΜ±υœδA«χΘΚ–¬œ Ώ≤Υ...” Εχ«“Θ§Έό¬έΡψΡΟ ≤Ο¥Θ§÷«Ρή÷ζ ÷ΕΦΜαΑοΡψΩΣΟ≈Θ§≤Δ‘ΎΡψΝ§–χΙΛΉς ±Θ§Φ«ΒΟΡψΗ’≤≈”ΟΙΐΒΡΙΛΨΏΚΆΈΜ÷ΟΓΘ
œ÷‘ΎΡψΟςΑΉΝΥΑ…ΘΩMCPΨΆœώΡ«ΗωΕ°ΡψΓΔΑοΡψΓΔΕχ«“±ξΉΦΜ·ΒΡ“÷«Ρή≥χΖΩ÷ζ ÷”Θ§ΕχΤ’Ά®API‘ρ «Ρ«Ηω≥δ¬ζ’œΑ≠ΓΔ–η“ΣΡψ«Ήάζ«ΉΈΣΒΡΡΑ…ζ≥χΖΩΓΘ
ΚΥ–ΡΈ ΧβΘΚΈΣ ≤Ο¥Τ’Ά®APIΒς”ΟΕ‘¥σΡΘ–Άά¥ΥΒ»γ¥ΥάßΡ―ΘΩ
‘Ύ…ν»κ Βάΐ÷°«ΑΘ§Έ“Ο«œ»“ΣάμΫβ¥σΡΘ–ΆΒς”ΟΤ’Ά®API ±ΒΡΙΧ”–Ά¥ΒψΘΚ
- »œ÷ΣΗΚΒΘ÷ΊΘΚΡΘ–Ά–η“ΣΦ«ΉΓΟΩΗωAPIΒΡœΗΫΎ——URL « ≤Ο¥ΓΔ–η“ΣΡΡ–©≤Έ ΐΓΔ≤Έ ΐΗώ Ϋ «JSONΜΙ «XMLΓΔ»œ÷ΛΆΖ‘θΟ¥–¥ΓΘ
- ΈόΉ¥Χ§ΫΜΜΞΘΚΟΩ¥ΈΒς”ΟΕΦ «ΕάΝΔΒΡΘ§ΡΘ–Ά±Ί–κΉ‘ΦΚ‘ΎΕ‘ΜΑάζ Ζ÷–Έ§ΜΛΉ¥Χ§Θ§’βΨΆœώ»ΟΡψΟΩ¥ΈΥΒΜΑΕΦ“Σ÷ΊΗ¥«ΑΟφΥΒΙΐΒΡΥυ”–ΜΑΓΘ
- ΙΛΨΏΖΔœ÷άßΡ―ΘΚ≥ΐΖ«ΩΣΖΔ’ΏΆ®ΙΐFunction CallingΜζ÷ΤΗφΥΏΡΘ–ΆΘ§Ζώ‘ρΡΘ–ΆΗυ±Ψ≤Μ÷ΣΒά”–ΡΡ–©ΙΛΨΏΩ…”ΟΓΘ
- Εύ≤Ϋ»ΈΈώΗ¥‘”ΘΚΒ±“ΜΗω»ΈΈώ–η“ΣΝ§–χΒς”ΟΕύΗωAPI ±Θ§÷–ΦδΒΡœΈΫ”ΓΔ¥μΈσ¥ΠάμΓΔ ΐΨί¥ΪΒίΕΦ–η“ΣΗ¥‘”¥ζ¬κ÷ß≥÷ΓΘ
ΕχMCP’ΐ «ΈΣΝΥΫβΨω’β–©Έ ΧβΕχ…ζΓΘ
#
»ΟΈ“Ο«Ά®Ιΐ“ΜΗωΨΏΧεΒΡ‘ΥΈ§ΦύΩΊ≥ΓΨΑΘ§Ω¥Ω¥¥σΡΘ–Ά‘Ύ≤ι―· ΐΨίΩβ ±ΒΡΝΫ÷÷≤ΜΆ§Χε―ιΓΘ
»ΈΈώ≥ΓΨΑ
”ΟΜß«κ«σΘΚ\"≤ι―·Ήι÷· ORG-001 ΒΡΉν–¬CPUάϊ”Ο¬ ΐΨί\"
’β «“ΜΗωΒδ–ΆΒΡ‘ΥΈ§ΦύΩΊ–η«σ——Ρψ–η“Σ¥” ΐΨίΩβ÷–’“ΒΫ÷ΗΕ®Ήι÷·ΒΡΉν–¬CPUΦύΩΊ÷Η±ξΓΘ
ΖΫΑΗAΘΚΤ’Ά®APIΒς”ΟΘ®¥ΪΆ≥ΖΫ ΫΘ©
ΡΜΚσΖΔ…ζΝΥ ≤Ο¥
Β±”ΟΜßΆ®ΙΐΤ’Ά®APIΖΫ ΫΧα≥ω’βΗω«κ«σ ±Θ§ ΒΦ ΒΡΙΛΉςΝς≥Χ «’β―υΒΡΘΚ
@app.route(\'/api/v1/metrics/cpu/latest\',methods=[\'GET\'])
defget_latest_cpu():
org_id=request.args.get(\'org_id\')
result=db.query(\"SELECT * FROM cpu_metrics WHERE org_id = ? ORDER BY timestamp DESC LIMIT 1\",[org_id])
returnjsonify(result)
functions=[
{
\"name\":\"get_latest_cpu_metric\",
\"description\":\"Μώ»Γ÷ΗΕ®Ήι÷·ΒΡΉν–¬CPUάϊ”Ο¬ \",
\"parameters\":
{\"type\":\"object\",
\"properties\":{
\"org_id\":{
\"type\":\"string\",
\"description\":\"Ήι÷·IDΘ§άΐ»γ ORG-001\"
}
},
\"required\":[\"org_id\"]
}
}
response=requests.get(
\"http://api-server/metrics/cpu/latest\",
params={\"org_id\":\"ORG-001\"},
headers={\"Authorization\":\"Bearer token123\"})
data=response.json()
final_response=f\"Ήι÷· ORG-001 ΒΡΉν–¬CPUάϊ”Ο¬ «{data[\'cpu_util\']}%Θ§≤…Φ· ±ΦδΈΣ{data[\'timestamp\']}\"
±©¬ΕΒΡΈ Χβ
- ‘ΛΕ®“εœό÷ΤΘΚΩΣΖΔ’Ώ±Ί–κΧα«Α‘ΛΦϊΥυ”–Ω…ΡήΒΡ≤ι―·–η«σ
- Ϋ©Μ·ΒΡ≤ι―·ΫαΙΙΘΚ»γΙϊ”ΟΜßœκ≤ι\"Ιΐ»Ξ1–Γ ±ΒΡΤΫΨυCPU\"Θ§–η“Σ–¬ΒΡAPIΕΥΒψ
- ΡΘ–Ά±ΜΕ·÷¥––ΘΚΡΘ–Ά÷Μ «¥ΞΖΔ‘ΛΕ®“εΚ· ΐΘ§ΈόΖ®ΝιΜνΒς’ϊ≤ι―·¬ΏΦ≠
- Εύ≤Ϋ≤ι―·άßΡ―ΘΚ»γΙϊ≤ι―·–η“Σœ»’“Ήι÷·ID‘Ό≤ι ΐΨίΘ§Νς≥ΧΜαΗϋΗ¥‘”
ΖΫΑΗBΘΚMCPΖΰΈώΒς”ΟΘ®÷«ΡήΖΫ ΫΘ©
’φ ΒΖΔ…ζΒΡ÷«ΡήΕ‘ΜΑ
‘ΎMCPΒΡ άΫγάοΘ§»ΟΈ“Ο«Ω¥Ω¥ΡΘ–Ά»γΚΈ÷ςΕ·ΥΦΩΦ≤ΔΆξ≥…»ΈΈώΘΚ
ΐΨίΩβMCPΖΰΈώΤςΒΡΙΛΨΏ«εΒΞΘΚ
-query_database(sql:string)->list:
÷¥––SQL≤ι―·≤ΔΖΒΜΊΫαΙϊ-list_tables()->list:
Ν–≥ω ΐΨίΩβ÷–ΒΡΥυ”–±μ-describe_table(table_name:string)->dict:
Μώ»Γ±μΫαΙΙ–≈œΔ-get_schema()->string:
Μώ»ΓΆξ’ϊ ΐΨίΩβΦήΙΙ
1ΘΚœ»≤ιΩ¥ ΐΨίΩβ÷–”–ΡΡ–©±μ
2ΘΚ≤ιΩ¥cpu_metrics±μΒΡΫαΙΙ
{\"columns\":
[{\"name\":\"id\",\"type\":\"integer\"},{\"name\":\"org_id\",\"type\":\"string\"},{\"name\":\"cpu_utilization\",\"type\":\"float\"},{\"name\":\"timestamp\",\"type\":\"datetime\"},{\"name\":\"host\",\"type\":\"string\"}],
\"primary_key\":\"id\"}
3ΘΚ÷¥––≤ι―·Θ§Μώ»ΓORG-001ΒΡΉν–¬CPU ΐΨί
[{\"cpu_utilization\":78.5,\"timestamp\":\"2024-01-20T10:30:00Z\"}]
\"\"\"
Ήι÷· ORG-001 ΒΡΉν–¬CPUάϊ”Ο¬ ΐΨίΘΚ
- CPUάϊ”Ο¬ ΘΚ78.5%
- ≤…Φ· ±ΦδΘΚ2024Ρξ1‘¬20»’ 10:30:00
- ΗφΨ·Ή¥Χ§ΘΚΗΟ ±ΦδΒψΚσΈόCPUœύΙΊΗφΨ· ΐΨίœ‘ ΨCPU Ι”Ο¬ ¥Π”Ύ’ΐ≥ΘΖΕΈßΘ®ψ–÷ΒΆ®≥ΘΈΣ80%Θ©Θ§Έό–ηΝΔΦ¥ΙΊΉΔΓΘ
\"\"\"
‘ΎTrea …œ―ί Ψ“Μœ¬ΘΚ
1ΓΔ Ήœ»‘ΎtreaΒΡ…η÷ΟΫγΟφmcpΡΘΩιΧμΦ”mcpΖΰΈώ
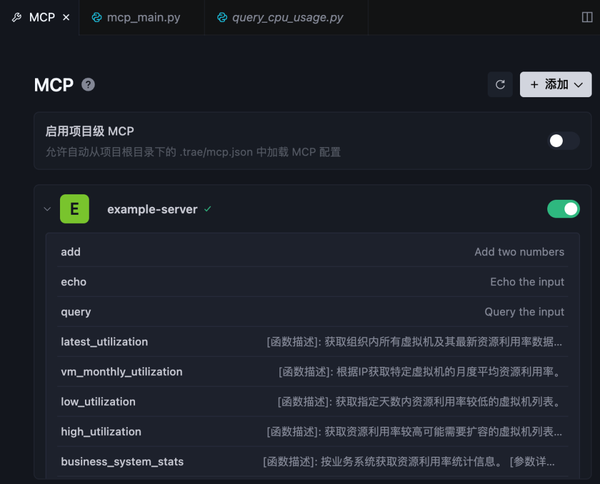
2ΓΔΈ ΜΑΖΫ Ϋ―Γ‘ώ build with mcpΘ§±μ Ψ Ι”Ο≈δ÷ΟΒΡmcpΖΰΈώΜΊ¥πΈ ΧβΓΘ»ΜΚσ―·Έ œύΙΊΈ ΧβΘΚ
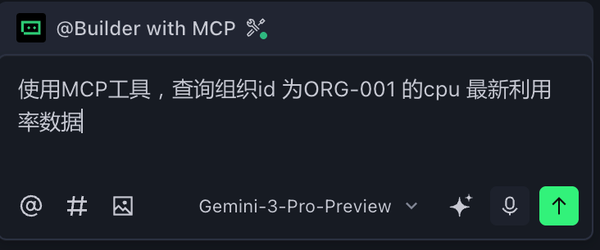
3ΓΔ¥σΡΘ–ΆΥΦΩΦ”ΟΡΡΗωmcpΙΛΨΏΖΰΈώΜΊ¥πΈ Χβ

4ΓΔœ‘ ΨΒς”Ο≥…ΙΠ
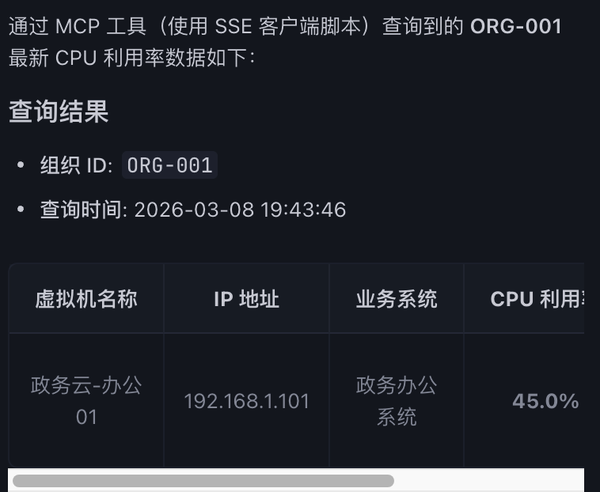
ΙΊΦϋ≤ν“λΕ‘±»
ΦΦ θ±Ψ÷ ΘΚ¥”\"≤ι―·ΙΛΨΏ\"ΒΫ\" ΐΨίΩΤ―ßΦ“\"ΒΡΫχΜ·
Τ’Ά®APIΖΫ Ϋ
- ΡΘ–Άœώ «ΒγΜΑΫ”œΏ‘±ΘΚ÷ΜΡήΫ”Ά®‘Λ…ηΒΡœΏ¬Ζ
- ≤ι―·ΡήΝΠ = ‘ΛΕ®“εAPIΒΡ ΐΝΩ
- ΥΦΈ§ΖΫ ΫΘΚΜζ–Β÷¥––
MCPΖΰΈώΖΫ Ϋ
- ΡΘ–Άœώ « ΐΨίΖ÷Έω ΠΘΚ’φ’ΐάμΫβ ΐΨίΘ§ΝιΜνΖ÷Έω
- ≤ι―·ΡήΝΠ = SQL±μ¥οΡήΝΠ × ΐΨίΫαΙΙάμΫβ
- ΥΦΈ§ΖΫ ΫΘΚ÷ςΕ·ΧΫΥςΓΔΆΤάμ≈–Εœ
ΉήΫα“Μœ¬
‘Ύ’βΗω ΐΨίΩβ≤ι―·ΒΡάΐΉ”÷–Θ§MCPΒΡ”≈‘Ϋ–‘Χεœ÷ΒΟΝήάλΨΓ÷¬ΘΚ
Τ’Ά®APIΘΚ
ΡΘ–ΆΥΒΘΚ\"Έ“÷ΜΡήΑοΡψ≤ιΉν–¬CPUΘ§’β «Ρψ“ΣΒΡ ΐΨίΘΚ78.5%\"
MCPΖΰΈώΘΚ
ΡΘ–ΆΥΒΘΚ\"Έ“≤ιΝΥ ΐΨίΩβΘ§ORG-001ΒΡΉν–¬CPU «78.5%Θ§‘Ύ’ΐ≥ΘΖΕΈßΡΎΓΘΈ“ΜΙΕ‘±»ΝΥΙΐ»Ξ7ΧλΒΡ ΐΨίΘ§ΖΔœ÷’βΗω÷Β¬‘ΗΏ”ΎΤΫΨυΥ°ΤΫ(65.3%)Θ§ΒΪΟΜ”–¥ΞΖΔΗφΨ·ΓΘ–η“ΣΈ“Ϋχ“Μ≤ΫΖ÷Έω«ς Τ¬πΘΩ\"
ΚΥ–ΡΆΜΤΤΘΚ
- ¥”±ΜΕ·÷¥––ΒΫ÷ςΕ·ΧΫΥς
- ¥”ΙΧΕ®ΙΠΡήΒΫΈόœόΩ…Ρή
- ¥” ΐΨίΑα‘ΥΒΫ÷«ΡήΖ÷Έω
’βΨΆ «ΈΣ ≤Ο¥MCPΡή»Ο¥σΡΘ–Ά’φ’ΐ\"άμΫβ\"ΚΆ Ι”Ο ΐΨίΩβ——≤Μ «Α―ΥϋΒ±Ής“ΜΗωΚΎΚ–APIΘ§Εχ «ΉςΈΣ“ΜΗωΩ…“‘Ή‘”…ΧΫΥςΓΔ…νΕ»Ζ÷ΈωΒΡ÷Σ ΕΩβΓΘ