

OSWorld 跑分 75%,人类测试者 72.4%。
3 月 5 日,OpenAI 发布 GPT-5.4,官方给出的最大卖点不是更聪明,而是——它能操作你的电脑了。
看屏幕、点鼠标、打字、选下拉框。不是生成一段代码让你去跑,是它自己动手。
我不太信。所以我决定自己试一下。
大家好,我是陆徐洲。
今天这篇文章,起因是后台一条让我印象很深的留言。
一位读者说,他被一个问题困扰了一两个月:每天从微信和办公 OA 收到 Excel 文件,然后要手动把里面的姓名、工号、金额一条一条录进内网的审批系统。

他试过 KeymouseGo,就是一个开源的按键精灵——录制鼠标键盘操作,然后原样回放。能用,但问题也很明显:系统弹个确认框、按钮挪个位置、数据格式变了,录好的脚本直接废掉。
他还问了一个更头疼的问题:外网收到的信息,怎么传到内网系统里自动操作?
说实话,这个问题我之前也没有好的答案。
但 GPT-5.4 发布之后,我觉得可以试试了。
先说清楚 GPT-5.4 到底更新了什么。版本号迭代很频繁,我只挑三个真正有价值的点。
第一,Computer Use。这是这次最值得说的能力。模型能看屏幕截图,理解界面上有什么,然后返回具体的操作指令——点击坐标 (354, 210)、输入\"张三\"、选择下拉选项。OSWorld 跑分 75%,超过了人类测试者的 72.4%。
有人可能会说,屏幕操作不是新东西。Selenium、Playwright 这些自动化测试框架早就能操作浏览器了,按键精灵更是十几年前就有的工具。
区别在哪?
Selenium 和 KeymouseGo 都是预编程的——你告诉它\"点击 id 为 submit 的按钮\"或者\"在坐标 (200, 300) 点一下\",它照做。它不知道自己在操作什么,屏幕上画面变了它也不知道。
Computer Use 是模型原生能力。GPT-5.4 是真的在\"看\"截图、\"理解\"这是一个报销表单、\"判断\"下一步该点哪里。界面变了,它重新看、重新判断。
简单说——KeymouseGo 是录像机,Selenium 是写好的剧本,Computer Use 是一个有眼睛的实习生。
第二,Tool Search。当 agent 接入几十个工具时,以前每次调用都要把所有工具的定义全塞进去,token 爆炸。现在模型能按需检索工具定义,实测省了 47% 的 token。对开发者来说,直接影响账单。
第三,整体效率提升。同样的任务,GPT-5.4 比前代用更少的 token、跑更快的速度完成。这不是某个酷炫的新功能,但对真正要用 API 干活的人来说,可能是最实在的升级。
说回实测。
我不可能拿读者的真实内网系统来测试,所以我自己搭了一个模拟环境。
一个 HTML 页面,模拟了一个叫\"星河科技\"的公司 OA 报销录入系统——有侧边栏导航、有表单输入框、有部门和费用类型的下拉选择、有提交按钮、有已录入记录的表格。看起来就像一个真实的内部系统。
然后准备了一份 CSV 测试数据,5 条报销记录,包含姓名、工号、部门、金额、费用类型、日期和事由。
核心脚本的逻辑很简单:一个循环。
截屏发给 GPT-5.4 → 模型看截图,返回操作指令 → 脚本在浏览器里执行这个操作 → 再截屏 → 再发 → 循环,直到模型认为任务完成。
它会用 Playwright 打开浏览器,更关键的是——Playwright 在这里只是一个\"手\",负责执行点击和打字。决定点哪里、打什么字的,是 GPT-5.4 在看截屏之后自己判断的。
运行之后,一个无头浏览器窗口弹出来,页面加载完毕。
然后它开始动了。
光标移向姓名输入框,点了一下,开始打字——\"张三\"。接着移向工号框,输入\"EMP001\"。到部门下拉框的时候,它点开下拉菜单,从选项里选中了\"技术部\"。
一条数据录完,它找到了蓝色的\"提交报销\"按钮,点击提交。页面弹出绿色提示\"提交成功\",下方表格新增一行。
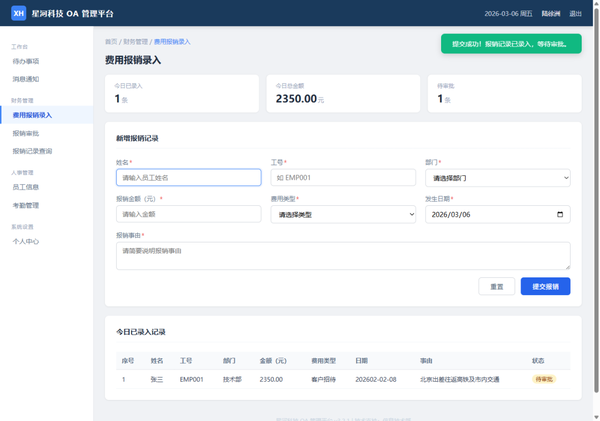
然后它开始填第二条。
整个过程有没有翻车?有的,操作不是很流畅。
[视频 1]
注:微信视频无法在 Markdown 中直接查看
请访问原文观看: https://mp.weixin.qq.com/s/heZCqGfXFNnHQQ8JnNOfTg
但总体来说,5 条数据录完,统计栏显示正确的条数和总金额。它确实做到了\"看屏幕理解界面,自主完成表单填写\"。
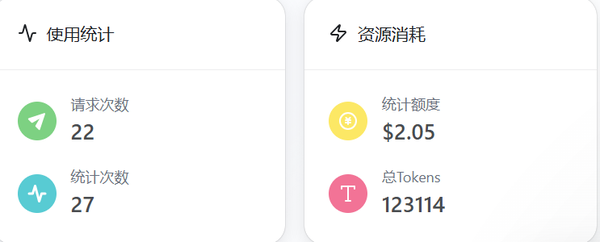
再看看单任务的模型消耗,GPT5.4还是有点贵的(这里是2元)。
回到那位读者的问题。
技术上,GPT-5.4 确实能完成\"看 Excel → 填系统\"这个操作。
但他的场景能直接用吗?
不能。三堵墙。
第一堵:内网进不去。GPT-5.4 是云端 API,必须联网调用。他的审批系统在内网,物理隔离。这不是配置问题,是架构问题。
第二堵:开源替代差距大。内网环境只能部署本地模型。目前最能打的开源 GUI 操作模型是字节跳动的 UI-TARS,72B 版本在 OSWorld 上跑到了 24.6%。作为参考,闭源模型这边 Claude Sonnet 4.6 已经到了 72.5%、GPT-5.4 是 75%——云端模型之间差距在缩小,但跟能本地部署的开源模型之间,还隔着三倍的鸿沟。
7B 版本可以在消费级显卡上跑,但成功率更低。简单说,无法无人值守。
第三堵:合规边界。这里要区分清楚——用 AI 去操作征信查询系统,自动发起查询,几乎一定违规。但如果是拿已经导出的征信报告 PDF 做内容解析和分析,那只是正常的数据处理工作,不涉及合规问题。
真正的红线在于:自动审批意味着责任认定不清——AI 点了\"通过\",出了问题谁负责?
画一张简单的图帮你判断自己的场景:
外网 + 非敏感数据 → 现在就能用 GPT-5.4内网 + 非敏感数据 → 可以试 UI-TARS,但成功率有限已导出的数据做分析解析 → 正常使用,不涉及合规自动操作审批系统、征信查询系统 → 制度上不允许
那这个方向到底有没有意义?
我引几段最近看到的观点。
Andrej Karpathy 在 X 上说了一句很重的话:\"coding agents basically didn\"t work before December.\"——编程 agent 在去年 12 月之前基本不能用。言下之意,12 月之后,能用了。
Simon Willison 说,自从 Claude Opus 4.5 和 GPT-5.2 发布以来,他手写的代码已经降到了总产出的个位数百分比。
Addy Osmani 在博客里写道,软件工程师的角色正在从\"实现者\"变成\"编排者\"——你不再自己写代码,你指挥 agent 写。
这些判断指向同一个方向:软件正在为 AI agent 重新设计。
GPT-5.4 的 Computer Use 是这个趋势的一个注脚。当所有系统都有 API 的时候,agent 直接调 API 就行。但现实是,大量系统只有 GUI、没有 API——内部 OA、审批系统、老旧的业务平台。Computer Use 就是为这些场景准备的后备方案。
一年前,最好的开源 GUI 模型跑分不到 5%。
现在 UI-TARS 已经到了 24.6%,GPT-5.4 到了 75%。
这个差距不会一直存在。
对那位读者来说,今天的答案确实是\"还不行\"。
但这个\"还\"字,可能比大多数人想的要短得多。
而在外网、合规的场景里——这个\"有眼睛的实习生\",今天就能上岗了。
我是陆徐洲,一家 LIMS 公司的 AI 算法负责人。
关注我,让我们一起在 AI 落地实践的路上,走得更远。
感谢您阅读我的文章。有任何关于AI提效或者工程落地实践方面的问题都可以加我微信,交个朋友,一起探讨,共同进步。