

2016中国应用性能管理大会运维自动化专场58到家架构师任桃术题为《58到家服务治理和跟踪系统》的演讲,现场解读了会重点讲解58到家在处理对系统性能的监控、流量监控、快速扩容等难点上的解决方案和监控系统的设计思路。
大家下午好,我叫任桃术,来自58到家。今天给大家分享的主要内容是《58到家服务治理实践》。
我们从三个方面来进行,第一个是为什么需要服务治理,第二个是58到家是怎样在服务治理这一块实践做了哪些事情,让系统能够更好的运行;最后是小结。
为什么需要服务治理?
早期58到家也是一个初创型的公司,包括家政、丽人、速运、三方平台,早期因为是初创公司大家都忙于满足需求的研发,很少对一些公共服务或者公共组件进行分装。
那时候我们有不同的研发团队在维护着不同的业务,所以说出现了很多类似的重复系统,比如说收银台,或者订单、支付系统等等。这样会导致什么问题?代码重复率高,可维护性非常差。另外我们在做一些测试或者开发,包括一些迭代更新的时候,如果没有一些公共服务,在每个不同业务线只要有一部分功能修改,所有的业线都都要做调整,无法做到敏捷交付。
另外在数据这一块,我们早期也是怎么快怎么做。很多业务系统的数据,之前是在一个大库里面大概有好几百张表,后续根据业务的特征,系统的职责做了一些解耦。初创性公司还是以需求响应快为目标,但是现有架构不能满足58到家迅猛的业务发展需求,所以我们有了后续一系列的动作。
服务化+立体化监控
做的就是服务化+立体化监控。首先要做的一件事情就是服务拆分,我们根据业务的特征以及系统的职责做了一些垂直划分,同时根据业务之间的交互处理,通过消息的方式实现了解耦做了水平拆分。通过服务化我们可以做到把之前一些工作的模块解耦,做到服务快速扩容。我们完成现有监控可以做到比较及时发现问题,不至于很被动的响应客服的投诉。
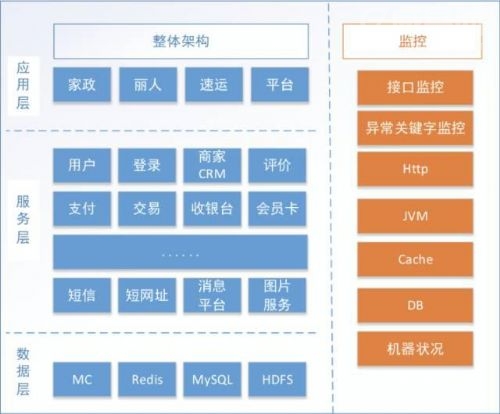
虽然做了架构升级,但是还是面临另外一个问题:我们服务化同时系统规模越来越大,整体架构越来越复杂,服务也越来越多,服务之间调用的关系也越来越复杂,导致在排查某一个问题时很可能出现整个调用链太长,在排查问题的时候无法很快的定位问题具体发生在哪一层,所以我们又做了后续的一些动作。
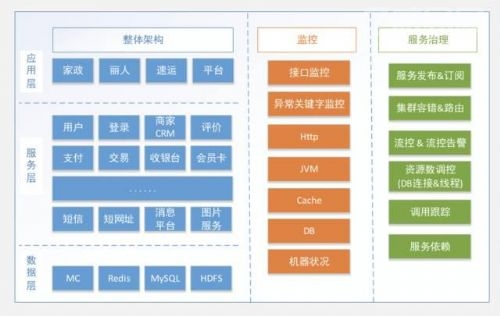
到家服务治理实践
今天主要讲一下58到家针对服务治理开展的事情。主要包括绿框里面的几部分内容,后续重点讲一下58到家是怎样在服务化治理的路上,做了哪些事情。
如果做服务化肯定要把服务的地址暴露出来,我们会有一个注册中心,这个中心的实现有多种。大致的做法是会把注册中心跟服务提供者和服务消费者联系起来,我们会有一个长链接的保持,当为服务方启动的时候,就可以把服务提供者的信息,包括服务的名称,或者服务的端口上报到注册中心。对于消费者来说,他们会根据业务的需要,将这些服务真正发起远程调用时从注册中心获取相应消费者的信息。我们做服务扩容,对于客户方来说对服务地址是无感知的。早期初创性公司在服务扩容的时候,是需要更改服务的一些配置节点,需要整体服务才能达到这样的效果。
另外就是基于注册中心,我们可以做服务的分组以及安全的测量。比如说不同的业务方会有不同的需求优先级或者说系统的重要性,我们会根据不同的业务方给它进行不同的服务分组,这样可以做到服务的隔离。
另外还有一些工作也是通过注册中心做的,我们可以做一些TCP心跳监测,保证服务的可用性。
高可用这方面,因为注册中心是一个强依赖的东西,不管是服务提供者还是服务的消费者,都是强依赖的组件,所以注册中心的重要性就不言而喻了,必须要保证注册中心的高可靠性。通过两个方面,一方面就是本身注册中心是有储备的。另外在消费者这边,当挖取到了注册中心服务提供方的配置信息之后,可以在本地做一个备份,这样就可以不再那么强依赖于注册中心了,这是服务的发布和订阅。
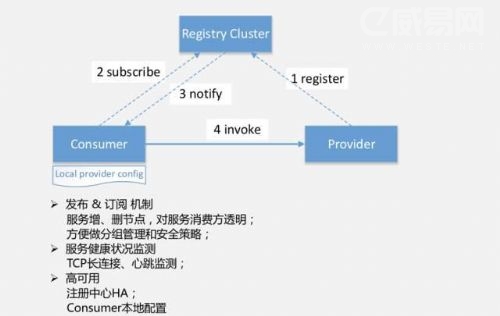
另外针对一个服务集群,需要做相应的服务集群路由和容错。
服务集群路由&容错
路由的方式,我们现在的是随机、轮洵、基于权重、基于负载的,无法根据现有服务器配置做负载的分发。基于权重也是初始化的时候,有一个静态的分配。负载比如说客户端根据服务器返回的响应时间,决定后续请求的分发。
其次,我们有一系列的路由策略现在也是配置化的,可以根据IP地址段做路由,同时可以根据方法名称,比如说要做读写分离,可以根据方法查询的,还是说更新的或是新增的,可以做不同的方法名匹配,再做相应路由。服务分组,我们可以根据实际业务的场景,业务的重要性,对服务进行分组,做相应的隔离。
另外还有一些特殊的需求,可能会根据某一些业务特征,需要把服务路由到固定的某一服务器上,根据特殊的路由规则提供路由的扩展,可以给业务线做相应特殊化的路由。
容错方面最主要一点就是故障转移。现在在做服务化的时候,我们都是要求是幂等的服务。做故障转移时如果一个服务不是幂等的,可能会出现我们本身不期望的结果。
失败缓存也有相应的机制,我们可以将失败的一些请求,在本地做一个延时的访问,再过段时间重试这个服务是不是可以了。失败通知与快速失败,也是为了更好的快速返回。
路由和容错这一块,在实践过程中间需要注意,首先我们必须保证服务是无状态。如果说真要是有一些跟状态相关的业务,我们建议是把它放到数据层,或者通过缓存的方式把跟状态有关的数据存储。当一个节点出问题的时候,我们重设可用的其他节点。
在重试过程中要注意一下会有一个延时,我们不可能无限制的做重试。因为在客户端一般往往会设置时间,如果客户端做了太多尝试,对应整个业务的返回已经没有必要重试了,因为业务方那边已经出问题了。这是在路由和容错这一块,我们做的一些事情。
流量控制&流量告警
为了对服务做一些过载的保护,我们做了流控和流量的告警。流控就是要保命,当我的请求不管是因为活动出大错,还是一些误操作或者非法调用导致整个数据请求突然上来之后,要做好相应工作。首先会设置一个流控的阈值,当访问量达到阈值80%的时候会有提前告警,不至于很被动的去解决问题,或者说没有相应足够的时间让我们去准备处理问题。
当真正发生流量高峰的时候,我们要做的事情理想的是自动扩容,现在是通过手动的快速扩容来做的。手动快速扩容必须辅助注册中心,消费者这边对服务的地址是透明的,客户方不用做任何调整,能够让客户端做到快速扩充。
做流控阈值的在线调整,这个时候可以做到实时生效的。之前设置的阈值可能不合理,或者没有到特殊业务场景,我们可以做到实时在线调整阈值。
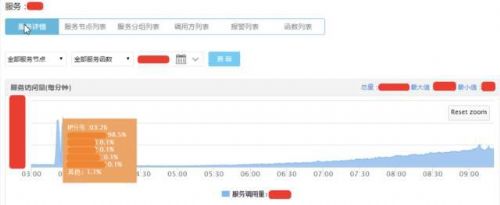
流量告警的话,我们会有的阈值,另外还有波段的阈值,这一分钟和上一分钟比较流量是不是有比较大的波动,如果有大的波动,不管是流量突然上升还是突然下降都有流量波动的告警,下图是58到家流控的页面,可以做到服务节点级别,对应服务的方法级别,现在是按每分钟的方式,通过数据缩减上报,实时掌握数据。
另外一个就是资源数的限制,数据库的资源数一般设置也是阈值,包括最小值和值。最小值主要是解决高峰突然来临的时候,数据库硬件如果真不够,可以提前预分配一部分硬件。的硬件也是对数据库更好的保护,如果数据库出问题了,整个服务基本上也会出问题。
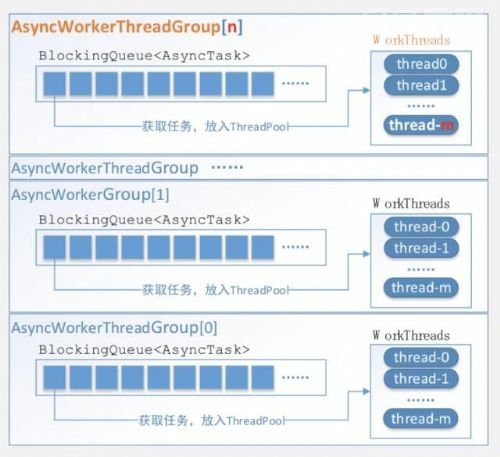
另外一个是工作线程数的控制,主要是通过线程模型。比如说IO线程跟未来的数据包放到对应的工作线程里面处理,通过对应的方式先把所有的请求放到一个对象里面,工作线程再从对象里面获取相应的任务。我们也借鉴了一些变化和实践,每个线程组会有一个工作对点,可以设置相应的性能数,实现配置多个线程组,每个线程组拥有字节统一的工作队列,减少在高并发情况下的竞争。对于线程组和每个线程组里面的线程数,现在都是可以做到联合的配置。
我们做服务化的时候,随着架构的升级服务数量会越来越多。在排查问题的时候,特别是一些业务非常复杂的服务,整个的调用链是非常长的。之前印象比较深刻,出来一个问题排查时间会特别长。针对现状我们做了服务工作系统,主要是基于日志的收集,我们开发了一个公共的日志组件,海量的日志上报都可以支持,每分钟会把相应的请求和调用相关的一些信息统一上报到日志收集平台。现在基本上涵盖了所用的全部框架,自研的Web框架、服务框架,以及相应的客户端和数据库的中间件,这些都是通过插件的方式,把每个框架的日志调用的信息统一上报到日平台,做一些实时的展示以及后续业务调用数据的分析。
这是我们的效果图。
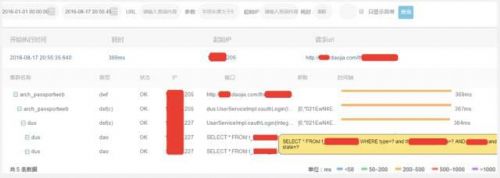
我们可以做到根据这个请求的参数,比如说前端有一笔订单的请求,可以根据订单的参数以及用户ID等等做一些调用的检索,特别是排查问题的时候,出现异常或者说服务的请求耗时特别长的时候,可以很快的从后台检索到有问题的一些调用链,进而做出一些优化。
调用跟踪系统,大致讲一下相关的技术点。首先就是整个调用链我们要从前端站点到服务层、数据层,整个调用关系或者调用链给串起来,主要依赖于两个元素:一个是有一个全局的调用的工作ID,把我们所有的调用请求通过这个ID给串起来,这样在定位问题的时候,可以排查到每个调用环节。另外还有一个调用的层级关系,比如说一个站点里面调了好几个服务,设计了评级调用关系。另外这个服务本身内部调了下游其他服务,也可以很方便的通过后台系统看得见。
由于是分布式的系统,整个调用链不是在某一台服务器上面可以全部搜集的到,往往是跨服务器,对于不同服务器之间调用链的数据怎么样透传?如果同一台服务器,同一个虚拟机里面的服务解决调用,我们是通过线上变量去做的这件事情。通过协议层面特别是跨服务器调用的时候,把这些数据放在协议里面,传输到另外一端。
另外调用链在推广的过程中发现了一个问题,当我们全量推调用链的时候数据量特别大。所以我们做了全量的调用链相关的数据采集和采样的方式,对于核心服务我们会有全量。采样也可以解决出了问题的时候可以比较快速的定位,一般情况下出问题的时候,会有一定的延续性,调用也是相对比较随机的,所以采样是可以采到有问题的数据。这是调用跟踪系统一些相关的实践工作。
调用跟踪系统可以发现每一次调用可能存在的问题,也可以以图形的方式很快的看到我们想要知道的一些数据,这是针对每一次调用。另外针对调用链,每天会做一个数据全量的分析,主要的目的就是说我们想知道整个或者说以集群为单位,这个集群下面依赖于哪些下游,然后我们给哪些上游提供相应的服务,这样可以反向的来推动服务架构的优化,因为有可能会出现像循环依赖或者说调用链特别长。而调用链特别长的原因,本身可能是业务的不合理,或者说本身设计的时候有一些拆分做得不是特别好,通过服务依赖以及调用链上报的数据,我们可以发现架构层面的问题,进而反推架构的优化。
最后是一个小结,今天主讲的内容主要是为什么我们要做服务治理以及58到家是怎样做的。服务治理一般是会伴随服务化去做一些服务的拆分,目的就是为了更好的解耦,为了更好的做服务扩容等等。
服务发布主要解决的是服务地址的透明化,以及基于注册中心的集中管理。
路由和容错主要是解决可用性以及服务负载的问题。
流控和告警主要是为了做过载保护。
数据库的链接数,线程数、资源数的控制,也是对服务做更好的保护以及可以怎样让我们的服务更好的响应客户端的请求,怎样提高闭环量。
最后一点是调用跟踪系统,面临着很多拆分出来的微服务,它们之间的调用关系特别复杂,为了更快速的定位线上问题所以我们有了调用跟踪系统,基于调用跟踪系统,可以根据调用关系去反推架构的优化。
关于APMCon:
2016中国应用性能管理大会(简称APMCon 2016)于8月18日至19日在北京新云南皇冠假日酒店隆重召开。APMCon由听云、极客邦和InfoQ联合主办的作为国内APM领域影响力的技术大会,举办的APMCon以“驱动应用架构优化与创新”为主题,聚焦当前最为热门的移动端、Web端和Server端的性能监控和管理技术,整个会议设置包含了:性能可视化、服务端监控实践、运维自动化、数据库性能优化、APM云服务架构和HTML5调优实践等话题,致力于推动APM在国内的成长与发展。