

亚马逊AWS首席云计算技术顾问 费良宏于基于云架构的性能优化专场发表了题为《AWS 云计算之上Linux实例的优化》的演讲,现场分享了AWS 上Linux 实例的深度优化和实践,这对于云计算的而言是最基础但却是不可缺少的一环。

以下为演讲实录:
费良宏:大家好,很高兴跟大家分享一些我最近关心的话题。在云计算上我们会使用很多的操作系统,Linux是我们非常熟悉、使用量非常大的系统,但是如何对这个操作系统进行优化,是大家面临的问题。Linux的历史比较悠久,但是在云计算之上的优化有一些需要特别注意的地方,也是今天我想跟大家分享的几个话题。
提到云计算我想先介绍一下AWS,大家可能知道AWS是云计算服务的提供者,到目前为止AWS在全球有13个区域,其中包括35个可用区,有56个边缘站点,这些构成了全球云计算的基础架构,服务于全球190个国家。
在过去的十年里通过这样的发展,AWS现在所提供的服务范围是非常广泛的,涵盖的种类不仅包括了计算、网络、存储、数据库、大数据、人工智能,还包括了像安全,甚至像SaaS等等一些新的云计算的领域。
在今年8月6号发布的云计算IaaS魔力象限里面,AWS又处于报告的绝对领先位置。在这个报告出现的6年时间里,每次AWS都处于绝对领先的位置,这个报告也代表了AWS在整个云计算市场的位置。
如果使用过AWS的人,恐怕第一个接触的产品都是AWS所提供的弹性虚拟服务器,我们称之为EC2,这个产品也是我今天谈的重点话题,也就是如何针对这样的环境进行优化。
大家都了解在云计算的环境里面包括在数据中心里面会有很多物理服务器,服务器之上通过虚拟化的技术会提供许许多多的虚拟机,如何使用这些虚拟机的资源,让它更好的服务于我们的应用,这是我们面临的一个很现实的问题。
回顾起来这样的技术发展有超过十年的时间,十年前第一代EC2产品种类比较单一,而且性能相对比较弱小。但是通过十年的发展,尤其是在过去三年里发展速度非常快,几乎每年都有很多新类型虚拟机的资源会发布出来。
面对这样的环境,我们使用的计算机资源如此丰富,我们可以通过AWS环境使用免费的操作系统,我们称之为Amazon Machine Image,这些操作系统包括Amazon Linux、CentOS、FreeBSD、Ubuntu、Debian等,同样也有大量付费的操作系统,包括Windows Server、Red Hat Enterprise Linux 、SUSE Linux Enterprise 版本等等。同样使用AWS提供的Marketplace资源,你可以大量的使用第三方甚至社区提供的各种Linux版本和分发的介质。在 Marketplace里面所有的Linux Image总数是1738个,几乎涵盖了所有主流的Linux版本。
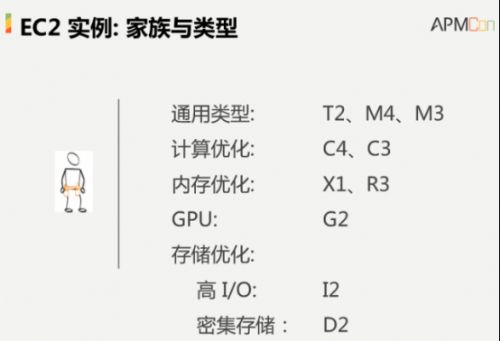
所有的EC2产品包含在十个大的家族产品里面,这些家族产品有各自不同的目的,分别适用于计算优化、内存优化、GPU、存储优化等等。其中一些产品代表了这个领域里面最高的级别,比如最新发布的S1就提供了2TB内存的处理能力,这些不同的机器可以满足大家不同程度的需求。

今天的话题是围绕EC2 Linux环境的优化,从这个简单的示意图可以看到,我们能够使用到的主要就是Guest、OS等,它们运行在一个虚拟层之上,之下是物理的操作系统。面对这样的环境,优化方式跟我们传统熟悉的Linux优化有很多的不同,这也是我今天强调的最重要的一点。
回到优化的问题,我们首先要决定优化的目的到底是什么?是决定改进我们的性能,那性能又是什么以及如何定义它?这是首先必须要回答的问题。由于我们的需求不同,对性能的要求有很大的差异。所以决定优化之前先从问题的视角出发,明确你的需求是什么。通常来看性能的表现取决于很多因素,这些因素可以归纳为三个大的方面,系统响应时间、吞吐量、一致性。当然性能不仅仅包括这些,我今天谈到的只是通用的方面。
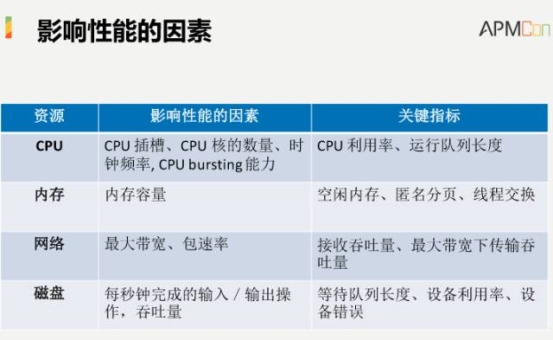
影响性能的因素从广义上来说非常多,但是围绕着操作系统这个环境来看,影响性能因素包括几个方面,第一个就是CPU,CPU插槽的数量、核的数量等等对CPU的表现有很大的影响。其次是内存,内存容量的多少直接影响到我们使用的资源所能承担的处理能力。网络的带宽、包速率也会对网络情况有很大的制约。磁盘的情况,包括吞吐量和每秒钟完成的输出/输入都是很大的影响,今天我们就是围绕这几个方面展开。除此之外还有很多因素都会对性能产生影响,但不在我们的探讨范围之内。
谈到云计算的性能问题必须要强调一点就是资源的利用率,在传统针对物理机的优化里面不是特别在意资源利用率,在低利用率的情况下我们还窃喜,因为还处在比较好的状态。云计算的环境,决定了云计算的成本是弹性可变的,如果不能很好的利用资源,使大量资源闲置,某种意义上会产生极大的浪费。所以对云计算环境下的优化来说,首先要考虑的是如何提高我们资源的利用率。从这个角度出发我的建议是,选择好的云计算的实例就等于优化,如果选择和你相匹配的实例就会最大程度发挥你的资源,使我们的成本在合理的范围内,并且未来随着我们需求的不断增长,我们的成本也会调整,不会让我们的每一分钱花在不必要的地方。
那如何选择实例呢?业内有很多经验和方法,这张图是Netflix奉献给业内的他们自己选择实例的流程图,依据不同的需求利用这个流程图就可以在为数众多的 AWS实例类型当中选择适合你的资源。这些资源其实还是非常复杂的,不仅仅是虚拟机涵盖的含义,以EC2 C4实例为例,实际是针对Intel E5-2666 v3 CPU定制的一款产品,算是一代面向计算优化的实例,更通用的类型。但是为了解决这个类型也做了很多优化,比如针对P-state和C-state 进行了定制化的配置处理。P-state和C-state实际上是CPU APCI的控制,决定了CPU是处于低功耗的状态还是处于一个从C0到CN不同运行状态处理能力的变化,可以使我们的服务器在能耗和性能之间保持一个合理的控制。同样每一款EC2的实例有不同的型号,有不同的处理能力,从large到8xlarge提供了不同的处理能力。
EC2的技术特性里有一些是需要让大家了解,并且可以应用这些技术进行优化,我大概列举了以下这些内容。
•CPU 指令核保护等级。对于X86这款CPU大家比较清楚熟悉,这款架构有明显的特征,就是指令核的保护等级,而且不能在用户模式下执行特权指令来保护系统,应用程序通过syscall实现内核调用的完成。比如我们针对一个Web服务器,使用strace就可以看到不同的调用,有效的减少这些调用可以明显提升性能。
•另外一个技术特点就是Intel VT-x,在2005年这款技术出现之前,我们的虚拟化主要使用PV的模式,PV模式存在很多不足,比如说需要穿透VMM,增加了延迟,系统调用的开销以及网络和存储系统的性能开销相对比较大,所以那时候我们对虚拟化的技术有很多顾虑。但是在2005年由于Intel增加了这个特性,我们出现了新的选择,使用硬件辅助的虚拟化满足了性能的提升。尤其是利用PV driver和HVM相结合,巧妙解决了处理较慢的操作,从此之后我们的虚拟化才大放异彩被业内广泛接受。
•Xen 虚拟化模式。大家知道Xen的稳定版本是4.7,它提供了五种虚拟化方式,包括HVM、PV-HVM、PV driver HVM、PVH等等五种不同的类型,对应到AWS EC2产品上,我们所说的HVM其实等价于PVHVM,前提是Linuxkernel支持。另外在AWS的网站上你会看到也会存在PV的描述,这就等价于Xen PV的模式。总结起来,我们在AWS网站上能够看到的所有的案例里面,性能最好得就是HVM的Xen版本,对应的就是PVHVM。从未来的发展来看,随着技术的不断进步,虚拟化技术也在不断提升,未来可能看到的性能预期比较好的就是PVH。
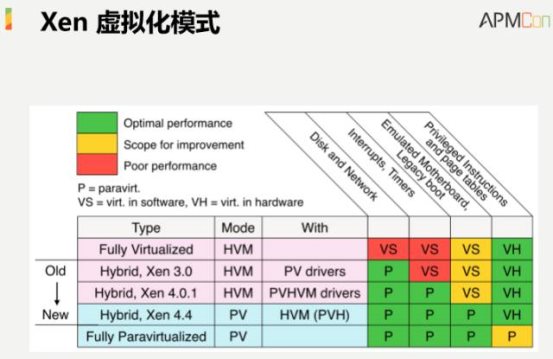
这张图里我归纳了刚才谈到的情况,当然这个版本相对老了一点,图上呈现的是4.4版本,目前是4.7版本,但总体的格局没有太大的变化。目前使用比较多的是 PVHVM的模式,未来可能会过渡到PVH的场景里面。通过几个不同的维度可以看到,PVH代表了未来速度最好的状态。
•另外一个特性是单根 I/O 虚拟化也就是SR-IOV,这个特性的出现是为了解决网络的特性,虚拟化会对网络性能产生损耗。于是Intel针对这种场景提供了几个方案,将PCIe的设备共享给我们每一个VM,某种意义上就解决了穿透的问题,使得我们的 VM可以直接访问PCIe的设备,就是网络的网卡。利用这个设备在AWS的环境里面就提供了增强联网的能力,比如C3、C4的实例,它们的某个特性就能达到10GB。最明显的是吞吐量会提高,并且降低了网络平均往返时延、减少了抖动 。需要强调的是不同的类型和型号,这个特性会有所差别,所以在选择的时候一定要强调你最好选择支持增强联网特性的类型,会得到一个更好的网络体验。
回到Linux内核这个话题,我们来看看针对刚才谈到的技术特点,如何利用技术手段帮助我们进行优化。我们简单来说有七大方面,就是CPU调度器、虚拟内存、巨型页、文件系统、存储的IO、网络、Hypervisor 。针对不同的场景会有各种优化的选项和策略,如果进行适当调整,在某种意义上对我们应用的性能会有很大的提升。

比如说如果安装了schedtool这款工具,这个工具可以通过GitHub搜索下载。使用之后可以针对每一个值进行特殊的处理,我在图中列出了一个特性,用B参数使长时间运行的进程得到一个非常好的性能优化,减少了上下文的切换。如果强调实时性,可以用R参数进行特定的优化。

针对虚拟内存,将swappiness设置为0可以释放出更多的内存。我们可以通过这些参数设定,使我们的系统更适合于我们内存消耗的需求。缺省的时候swappiness是打开的,并且值是60,我们可以改成10更好地提升性能。
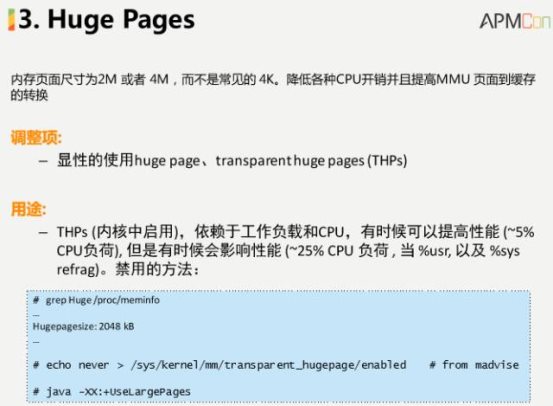
巨型页也是内存访问上重要的特性,常见的内存管理是通过内存配置的方式进行管理,缺省的情况是4K,那么如果有1GB内存,就会有26万页的管理项,如果内存更大就会更加庞大。我们经常会在这样大的表中进行查找,如果数据量非常大,某种程度上会影响使用的效率。缺省情况下在EC2的某个实例里面将页设置为 2M,你也可以设置成更大的值。在不同的应用里面都会对page进行很好的设置。

文件系统是很特别的应用场景,需要我们引起注意。不同的文件系统有很多可调整的参数,通常这些优化的项目都围绕这几个参数进行,包括background flush earlier、 aggressive flush later等,这些都依托我们具体的使用环境和需求完成。以dirty_background_ratio为例,缺省情况下是10,这里设置为5来提高响应速度和处理能力。

Storage I/O主要是针对块设备进行优化的调整项,大家知道在操作系统里面,Linux操作系统支持预读的能力,它可以预知下一个要读取的文件,将它读到内存里。环境变化了,目前很多应用软件对这个特性是非常敏感的,这种情况下我们可以对read ahead size进行一些优化和调整,甚至可以把它禁用。另外SSD出现之后,使得我们传统的调度方法产生了变化,比如我们经常采用的调度策略是CFQ,它对 SSD就不是非常友好,更好的方法我们推荐使用“noop” scheduler,所以可以通过这样的一些改变使得我们更好地匹配SSD获得不同应用场景的需求。
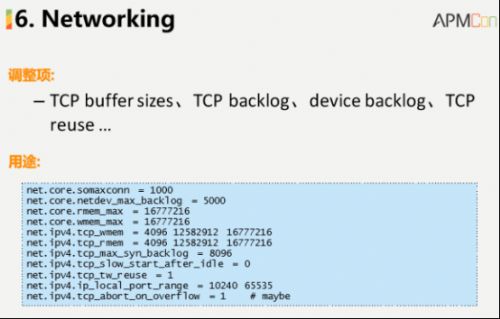
对于网络,大家都很清楚,我们有很多的网络优化项进行调整和设置,这些优化项种类和数量非常多,其中包含了像buffer sizes、backlog等,这些项大家可以针对具体的经验进行优化处理。

还有一种应用场景就是在虚拟化的环境里面,云计算里面经常会遇到的,针对Hypervisor 的优化。最主要的优化项就是clocksource,包括像hpet、xen、tsc等等。
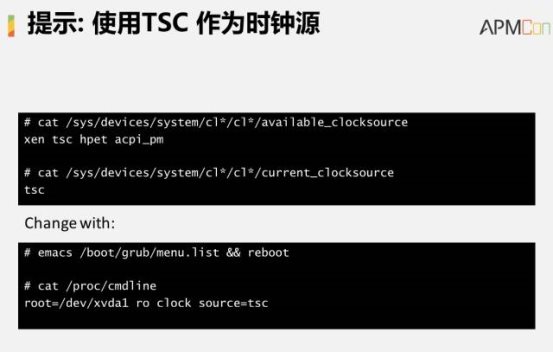
在我们的环境里缺省的EC2时钟源都是Xen,如果你用cat命令读取都是这样的。这里面有什么区别呢?简单来说hpet是一个硬件的时钟源,它提供了非常好的监控,但是它需要产生系统的调度,开销比较大。Xen的适用性非常好,所以在虚拟化环境里面缺省会使用它。tsc是通过计算器的方法获得这样的时钟源,并不需要用系统调度来实现,只需要在用户空间就可以得到,但相对来说精度不如hpet,但是速度上tsc是最好的表现。所以你可以尝试把时钟源设置为tsc进行观测。比较理想的情况下,CPU的用量可以降低30%,当然如果表现不好也会产生额外的副作用。

我们刚才提到了监测,在AWS的环境里面有很多服务可以帮助我们达成这个目标。以这个WebServer为例,在这个场景里面,可以通过监控看到不同WebServer请求的表现,也可以看到内存的使用情况,包括磁盘的统计情况、网络的使用统计等等,所有的监控指标都是我们进行优化的非常重要的基础条件。

优化时也会有一些不好的优化场景,希望大家引起注意。第一种是“打地鼠” 式的优化,这个是什么样的场景呢?就是随机的调整参数,你尝试着或者说猜测性的对参数进行调整,并没有直观的逻辑关系证明它会有影响,你只是在赌博。如果现象消失了你可能假设的认为这种方式取得了效果,这种方式其实有很大的偶然性,并不能很好的解决问题,所以要尽量避免。另一种是“街灯”式的优化,只看到了眼前一点点的情况,就是选择自己熟悉的工具或者随便从互联网上找到一个工具,甚至随机选择一款工具就作为你参考的依据,这些方法都有很大的弊端。

一个比较有效的方法我们强调是基于观察,使用一些统计工具观察系统的性能和资源的使用情况,用数据来证明你的优化是高效的。从使用方式来看就是对硬件和软件的组件,逐一进行分解,研究每个组件可以调整的参数,并且有一个明确的、量化的预期,通过调整参数看能不能满足预期来达到优化目的。

这里面特别强调的一个方法,叫做USE,就是利用率、饱和度和错误数。这个方法在一本书里面讲的非常详细,叫做《Systems Performance》,它就强调了用利用率、饱和度、错误数这三个维度帮助我们进行调整优化,在这本书里有非常详细的描述。

除了刚才谈到的方法之外还有一些地方需要大家考虑:
•在云计算的环境里面,有的时候复杂的问题并没有明确的答案,即使是你做了尝试和调整也没有答案,有可能是你需要换一个实例了,比如换一个更大的型号或者更强劲的实例才能帮助解决问题。
•有时候分析之后确认与实例有关,但是大多数可能与应用有关,这从统计数据来看符合80/20原则,也就是说80%可能性与应用有关,只有20%是跟基础架构操作系统有关的。简单来说80%是跟应用程序本身有关的,通过程序的优化和重构就可以满足或者解决应用问题,只有20%的场景里面你需要对操作系统基础架构优化,才可以解决,大家一定要记得,不要上来就尝试对操作系统进行太多的优化,可能欲速则不达。
•有些场景会有些意外,比如说延迟异常的场景,20%是由代码引起的,更多的因素是由实例的类型、网络的选择、垃圾回收等产生的。
在分析方法上,对于负载的分析,建议是自顶向下,从应用的负载着手,然后分解请求时间。对资源的分析建议自下而上,从资源的性能开始着手,然后是工作负载,大家在分析的时候可以灵活掌握。
对于性能工具,除了云计算平台提供的观察工具之外还有一些系统的工具,可以对操作系统的核心进行很好的统计,这里我们介绍四大方面的工具给大家参考。
•Statistical 工具即统计工具,包括vmstat、pidstat、sar等等。需要强调的是这些工具没有安装到AWS EC2的缺省环境里面,需要手工安装,安装之后你可以看到对网络状况非常详细的统计。
•profiling 工具,就是对CPU堆栈进行跟踪,解释CPU的使用情况,对内存对象进行跟踪,解释内存的使用情况,产生的调优就是对热代码的路径进行调整和配置,比如热代码的问题,如果定位以后可能是真正的瓶颈,你可以聚焦在这点解决最终最根本的问题。另外对频繁的对象的分配,尤其是内存使用上,也可以利用这些方法和工具帮我们解决它。针对这个程序有很多不同的profiling工具,这里面推荐的就是Lightweight Java Profiler 的工具。
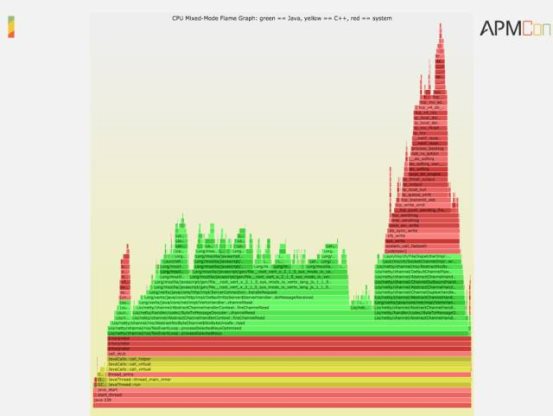
LJP 是一个开源的项目,主要针对java。优点有两点,第一就是精度非常高,第二就是支持火焰图的输出。火焰图是一个非常好玩的东西,也非常直观。下面是一个火焰图的例子,其实非常简单,Y轴是堆栈的情况,X轴是取样频度的情况。通过这个图既使你没有太多的时间或者缺少经验也可以帮助你定位到一个方向,从而优化和解决问题,所以火焰图是比较推荐的方法。系统的profiling是一个perf的工具,perf也可以生成CPU的火焰图,火焰图这个工具也是开源项目。
•Tracing的工具非常多,包括ftrace、perf_events等等,不给大家特别强调了。需要给大家强调的就是ftrace,现在已经是Linux的组成部分了,如果你打开代码的话可以在原代码当中看到。iosnoop是一个开源项目,大家用这个名字可以下载到,但是需要你编译一下,小小的工作并不复杂。而且我的经验来看,绝大多数Linux环境里面依赖库并不复杂,工作量蛮小的。
•Hardware 计数器。比较特别一点的就是MSR,就是硬件的计数器,通过这个计数器提供了很多基本的信息,不同的型号会有差别。在大部分AWS EC2的实例中都已经支持MSR的特点了,利用这个特点就可以完成很多对CPU低级别的监控操作。其实MSR工具也是一个GitHub的工具,它能做很多有意思的事情,比如说对CPU的型号、频率、状态等等进行数据的获取,然后通过这些数据定位你所需要的一些信息,就可以找到你需要调优的几个点。
归纳起来今天讲了很多工具,讲了一些需要注意的原则。我想把最后这三点作为总结分享给大家的经验。
•第一,在云计算环境里面,由于我们面对的环境不同于物理环境,有更多的虚拟资源,有更多的选择项。对于优化的场景来说,选择一个合适的实例就等于性能优化,大家千万不要小瞧这个结论,也是很多的经验换来了。
•第二,按照80/20原则,在需要的时候你可以使用Linux内核、性能优化或者统计的方法进行观察,并且基于数据实现对核心的调优。最重要的是所有的优化都是基于监测的结果,都是由数据驱动的,所以千万不要忽略掉。
•使用你手上所有的工具,包括云计算平台上的工具、操作系统自带的工具以及我们可以下载的工具来获得你的数据,用数据来说服你选择哪一个优化的方向。
