
我们知道,社交图谱记录我们在社交媒体上的种种关联。从搜索结果到优惠券,基于社交图谱的服务已经屡见不鲜。在这同时,一个定位更加精准的个人化网络正在慢慢崛起——基于用户个人喜好的兴趣图谱网络服务。现在已经有一些分散的兴趣图谱,比如谷歌的个人化搜索,或者Amazon的推荐引擎。有些公司希望这种服务可以覆盖我们全部的网络生活,而这就意味着,我们的所到之处所见之物,都是我们的心之所向。意味着我们不再需要在新闻网站上搜索喜欢的故事,或在购物网站上查找需要的商品——因为一旦登陆这些网站,网站系统就会自动识别我们是谁,我们喜欢什么,并呈现我们所需的内容信息。
不管这种构想带给你的是惊喜还是恐慌,我们都应该看看这种完全个人化的网络具体是怎样运作的。
发现你喜欢什么
事实上,Twitter和Facebook等社交网站在确定人们的实际兴趣时,或许并没有像在其他网站上的点击或者评论那么有效。很多人在Twitter上分享信息是因为职业需要,用户很多时候在Facebook上分享的信息也仅限于为交际圈服务。不管是在哪种情况下,“很多时候,人们都只是在作秀,以期给人留下好印象。这就导致了用户数据的不完整。”
那兴趣图谱是怎样工作的呢?创业公司Gravity正是基于这一服务的一家公司,其CTO Jim Benedetto向我们介绍了网站的工作原理。Gravity同时为多家网站服务,它会跟踪用户在其所有服务网站的行为,这样用户在登陆任意网站时,都能自动获得特色内容。你可以点击这里看到网站构建一幅图谱的具体流程。
从技术层面来说,Gravity是通过一个基于Freebase 和 DBpedia等多个数据集的大型数据引擎,确定用户在点击某篇文章或发表某个评论时的实际兴趣点。举个例子,一个用户如果发表Vanessa Laine(湖人队NBA球员科比的前妻)的Tweet,那他应该是对篮球更感兴趣,而不是Laine的出生日期或者其他确切但不相关的信息。
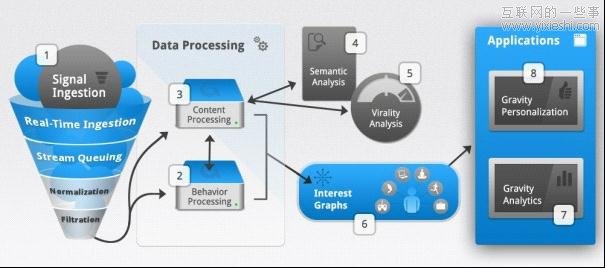
随身携带“个人标签”
有一天,人们不管是浏览什么网页,都可以基于自己的兴趣。
这确实是一个引人注目的愿景:我们的兴趣图谱会影响我们在任意一个网站上看到的内容。如果你喜欢滑雪,那你可能就会在电子商务网站上看到滑雪设备的相关交易信息。而且,很有可能你都不用登陆就能看到这些信息,因为这些网站会综合考量你在整个网络的行为。
尽管现在已经有一些分散的兴趣图谱,但真正的难点是,如何将这些分散的,零碎的兴趣图谱整合成一个统的关于我们是谁,喜欢什么的个人标签。有可能,诸如OAuth(允许基于API的数据可以在不同服务间共享)这样的方法会起作用。这样你在上网的时候只要登录一次,你的兴趣图谱就处于驱动状态,并让整个网络基于你的需求为你服务。
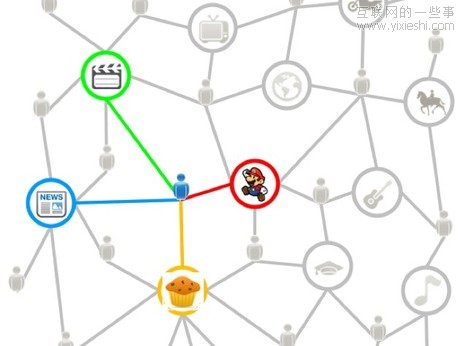
真正为你所用
当然,尽管很多人会喜欢这种个人化的上网体验,也会有人担心隐私问题。而且,有人会希望自己可以随意上网,而不是由网站来预测他们喜欢什么。基于这个原因,这种个人化的网络必须是可选服务,而不是必选服务。
隐私问题是一个棘手的问题。所以,用户应该有权决定他们的哪些上网记录会成为他们个人标签的一部分。举个例子,大部分喜欢色情视频的用户都不希望他们的这一喜好,会影响他们被推荐的新闻内容,或者当他跟女朋友在观看某个比赛时,网站突然推荐色情视频。所以,网站必须设定相应的授权按钮,以及“请勿追踪”按钮,以确保这种个人化的网络不会成为用户的绊脚石。
尽管我们有可能会很喜欢这种个人化的网络,但是凡事都应该有一个度。所谓的个人化网络服务,除了保证网络信息呈现的个人化以外,还应该保证服务本身的人性化,真正为用户所用。